
![]() DDLL (211.♡.71.228)
DDLL (211.♡.71.228)
2024년 5월 14일 AM 12:21
기존에는 컴퓨터가 모은 SP 개수 내에서, 제출 가능한 명령을 랜덤하게 추출하는 방식으로 공격 명령을 설정했었습니다.

노란색 동그라미가 SP 포인트
(SP는 매 턴마다 1씩 축적됩니다.)
그런데 이렇게 되면, 스테이지가 바뀌더라도 플레이어는 매번 똑같은 컴퓨터와 플레이를 하는 것과 같아서 질려버릴 것 같았습니다.
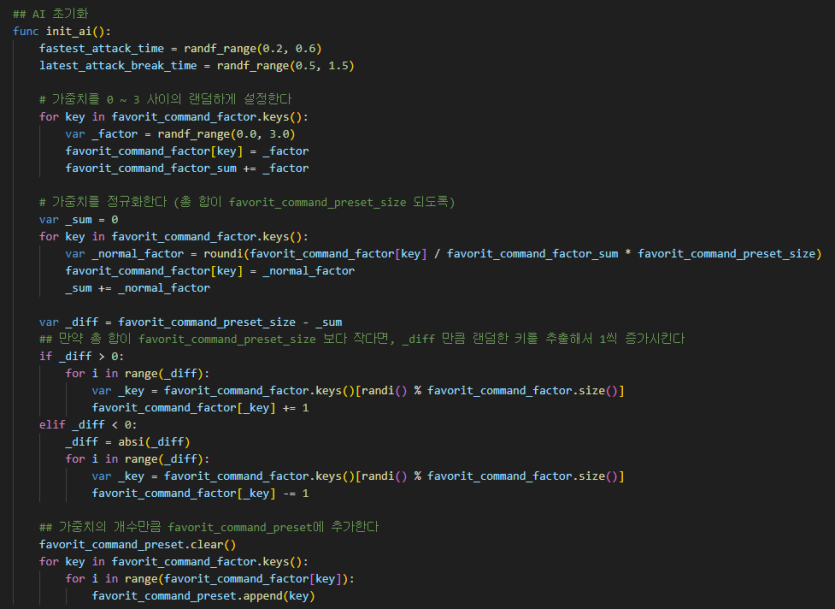
그래서 컴퓨터가 낼 수 있는 각 패에 대해서, 선호하는 가중치를 매 스테이지마다 초기화하도록 했습니다.
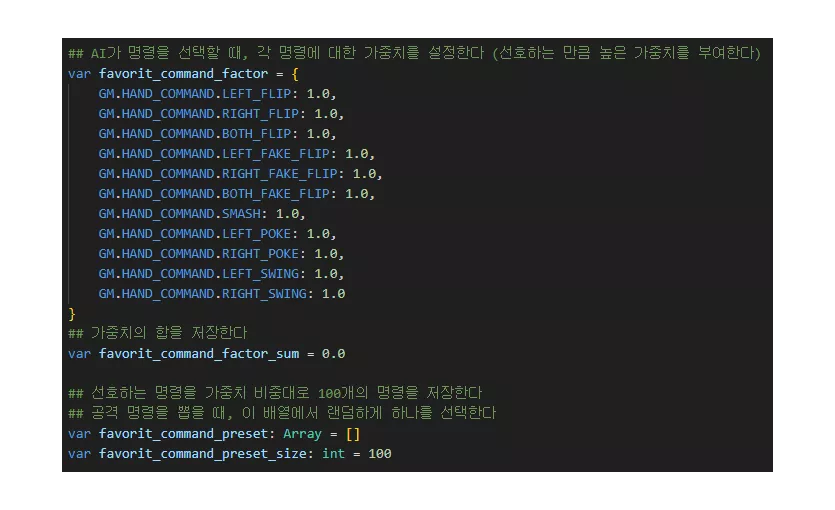
공격 가능한 명령은 뒤집기, 가짜 뒤집기, 두드리기, 찌르기, 훑고 지나가기
favorit_command_factor 변수에 공격 가능한 명령별로 가중치들을 저장할 수 있도록 구성하고
favorit_command_factor_sum 변수에 랜덤하게 설정된 가중치의 합을
favorit_command_preset 변수에는 가중치 비율대로 favorit_command_preset_size 개수 만큼의 명령들을 배열로 저장하도록 했습니다.
이 내용을 구현한 init_ai() 메서드를 작성합니다.
그리고 매 컴퓨터의 공격 턴마다 다음과 같은 decide_attack_command() 메서드를 통해서 명령을 선택하도록 했습니다.
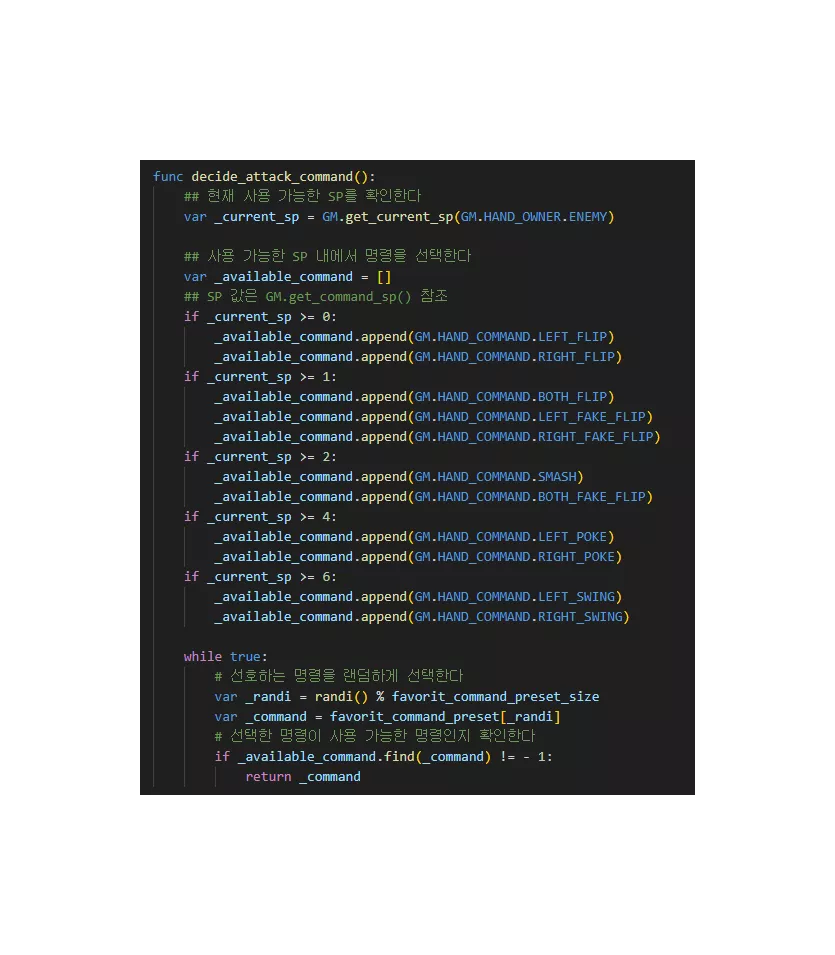
아직은 테스트를 많이 해보지 못해서, 이런 로직이 플레이어에게 상대 컴퓨터가 선호도를 갖고 있는 것 처럼 느끼게 하는지는 잘 모르겠습니다.
짧게 플레이 해 본 바로는, SP 값이 매 턴마다 1씩 증가하다보니, SP를 0~1 만큼 소모하는 명령을 주로 발생시키면서 SP 값이 쌓이는 기회가 잘 없는 것 같아 개선이 필요하지 않나 생각됩니다.
갖고 있는 아이디어로는, 공격에 성공했거나 연속 공격에 성공할 경우, 아이템을 사용하는 등으로 SP를 추가로 획득하는 루트를 만들어주면 어떨까 싶네요.
컴퓨터가 패를 선택하도록 게임을 만들어본 경험은 처음이라 이렇게 AI를 만들어 가는게 좋은 방법인지 모르겠습니다.
혹시 다른 좋은 방법을 아신다면, 간단하게 키워드라도 말씀해주시면 공부하는데 많은 도움이 될 것 같습니다.
긴 글 읽어주셔서 감사합니다.
첨부파일
Video.mp4 2.3 MB댓글 (0)
- 아직 댓글이 없습니다. 첫 댓글을 작성해보세요!
댓글을 작성하려면 이 필요합니다.