


yanolja/EEVE-Korean-Instruct-10.8B-v1.0 로 Streamlit과 연동하여 만든 고등학교 과학 챗봇
알림
|
페이지 정보


작성일
2024.06.30 11:43
본문
안녕하세요?
모든 것을 오픈 소스로만 만들어 보고 싶어서 앤스로픽이나 오픈AI 모델을 안 써 보려고 대학원 연구실 서버에 올라마로 yanolja/EEVE-Korean-Instruct-10.8B-v1.0 를 불러와서 Streamlit과 연동시켜 학교 교재와 제가 가지고 있던 학생 질문-답변 데이터셋으로 RAG를 적용하여 답하게 만든 고등학교 통합과학 챗봇을 만들었습니다.
서버 사양이 Intel Core i7 13700K에 Nvidia Geforce 3060 12GB로 그닥 좋지 않아서… 언어 모델을 하나만 올릴 수 있다 보니 동시에 질문이 들어오면 순차적으로 처리하느라 시간이 많이 걸릴 것 같습니다.
학생에게 공개하여 써 보게 하고는 있는데, 동시접속이 얼마나 될지 모르겠습니다.
http://acer2.snu.ac.kr:8501 에서 쓸 수 있습니다.
부족한 부분을 알려 주시면 고쳐보도록 하겠습니다. ㅎㅎ 감사합니다.
수정: RaPo님 덕에 기본 모델을 구글의 gemma 2 9B 양자화 모델로 교체했습니다. 비슷한 메모리를 소모하면서 성능은 더 좋아졌습니다.
댓글 12
/ 1 페이지
kungmo님의 댓글의 댓글
@브루스님에게 답글
좋게 봐 주셔서 감사합니다. 오픈소스 한국어 언어모델이 이 정도로 말을 잘 알아듣고 말을 잘 만들어 내서 신기합니다. 질의응답 데이터셋 만들기는... 정말 고된 작업 같습니다.
RaPo님의 댓글


LLM이 하나만 있기 때문에, 대답 자체서 오래 걸리게 되면 다른 사람들은 다 기다려야 합니다.
12기가면 EEVE가 4비츠 양자화 해서 7.5기가 정도 점유하게 됩니다.
올라마로 RAG에 사용할 임베딩 모델을 하나 더 올려서 작업을 분산시켜줘야 좀 더 빠를것 같습니다.
올라마에 임베딩 모델이 두 개 정도 지원되는데 그걸 사용해보세요.
올라마 도커로 각각 사용하시는게 좋습니다.
12기가면 EEVE가 4비츠 양자화 해서 7.5기가 정도 점유하게 됩니다.
올라마로 RAG에 사용할 임베딩 모델을 하나 더 올려서 작업을 분산시켜줘야 좀 더 빠를것 같습니다.
올라마에 임베딩 모델이 두 개 정도 지원되는데 그걸 사용해보세요.
올라마 도커로 각각 사용하시는게 좋습니다.
kungmo님의 댓글의 댓글
@RaPo님에게 답글
맞습니다. 지금 LLM이 하나만 돌아갑니다.
양자화된 EEVE 10.8B Q8 GGUF 모델을 GPU에 올리면 8GB 조금 넘게 차지합니다. 올라마에서 쓰는 Sentence-BERT 임베딩 모델은 bespin-global/klue-sroberta-base-continue-learning-by-mnr 을 쓰고 있습니다. 그래서 둘을 같이 쓰면 10GB 정도 쓰니 빠듯합니다. ㅎㅎ
RaPo님 궁금한 게 있습니다. 작업을 분산하려면 모델을 더 올려야 한다셨는데요, 한정된 VRAM에 모델을 하나 더 올리는 방법이 무엇인지 감이 오지 않습니다. 임베딩 모델을 두 개 정도 지원한다는 게 무슨 뜻인지 알 수 있을까요??
써 주시고, 의견까지 주셔서 정말정말 감사합니다!
양자화된 EEVE 10.8B Q8 GGUF 모델을 GPU에 올리면 8GB 조금 넘게 차지합니다. 올라마에서 쓰는 Sentence-BERT 임베딩 모델은 bespin-global/klue-sroberta-base-continue-learning-by-mnr 을 쓰고 있습니다. 그래서 둘을 같이 쓰면 10GB 정도 쓰니 빠듯합니다. ㅎㅎ
RaPo님 궁금한 게 있습니다. 작업을 분산하려면 모델을 더 올려야 한다셨는데요, 한정된 VRAM에 모델을 하나 더 올리는 방법이 무엇인지 감이 오지 않습니다. 임베딩 모델을 두 개 정도 지원한다는 게 무슨 뜻인지 알 수 있을까요??
써 주시고, 의견까지 주셔서 정말정말 감사합니다!
RaPo님의 댓글의 댓글
@kungmo님에게 답글
올라마는 1:1 구조라 생각하시면 됩니다.
요청은 큐에 쌓이고 큐에서 꺼내지는 순서대로 답변을 한다는 것이죠.
그래서 두 명이 동시에 질문하면 0.1초라도 먼저 들어간 사람의 답변이 나오고 다음 유저는 마냥 기다려야 한다는 말입니다.
12GB 램은 구글 젬마2 4비트 양자화 모델로 2개 정도 올라마를 올릴 수 있을 것 같습니다.
올라마에서 공식적으로 지원하는 모델은 아래 리스트에서 확인해보시면 됩니다.
https://ollama.com/library
한정된 자원에서 서비스를 하려면 성능을 손해봐야 하는데, 그건 님께서 테스트를 하셔서 성능상 큰 차이가 없는지는 확인하셔야 합니다.
올라마에서는 임베딩 모델이
nomic-embed-text
mxbai-embed-large
snowflake-arctic-embed
이렇게 세 모델을 공식 지원하고 있습니다.
임베딩 관련 내용은 아래 링크를 확인해보세요.
https://discuss.pytorch.kr/t/ollama/4039
결론적으로 더 작은 모델로, 동일한 성능(원하는 대답)을 낼 수 있게 구성해야 사람들이 원활하게 사용할 수 있습니다.
우리가 네트워크 인프라까지 구성해서 로드밸런싱으로 원활한 서비스를 만들어낼 필요는 없겠지만,
LLM을 2개 올릴 수 있다면, webui 주소를 2개로 나눠서 2명은 원활하게 사용할 수 있지 않을까 합니다.
올라마는 VRAM이 허락하는 한 도커로 몇 개씩 올릴 순 있습니다.
도커로 올릴 때, 내부 포트 번호만 다르게 하면 됩니다.
요청은 큐에 쌓이고 큐에서 꺼내지는 순서대로 답변을 한다는 것이죠.
그래서 두 명이 동시에 질문하면 0.1초라도 먼저 들어간 사람의 답변이 나오고 다음 유저는 마냥 기다려야 한다는 말입니다.
12GB 램은 구글 젬마2 4비트 양자화 모델로 2개 정도 올라마를 올릴 수 있을 것 같습니다.
올라마에서 공식적으로 지원하는 모델은 아래 리스트에서 확인해보시면 됩니다.
https://ollama.com/library
한정된 자원에서 서비스를 하려면 성능을 손해봐야 하는데, 그건 님께서 테스트를 하셔서 성능상 큰 차이가 없는지는 확인하셔야 합니다.
올라마에서는 임베딩 모델이
nomic-embed-text
mxbai-embed-large
snowflake-arctic-embed
이렇게 세 모델을 공식 지원하고 있습니다.
임베딩 관련 내용은 아래 링크를 확인해보세요.
https://discuss.pytorch.kr/t/ollama/4039
결론적으로 더 작은 모델로, 동일한 성능(원하는 대답)을 낼 수 있게 구성해야 사람들이 원활하게 사용할 수 있습니다.
우리가 네트워크 인프라까지 구성해서 로드밸런싱으로 원활한 서비스를 만들어낼 필요는 없겠지만,
LLM을 2개 올릴 수 있다면, webui 주소를 2개로 나눠서 2명은 원활하게 사용할 수 있지 않을까 합니다.
올라마는 VRAM이 허락하는 한 도커로 몇 개씩 올릴 순 있습니다.
도커로 올릴 때, 내부 포트 번호만 다르게 하면 됩니다.
kungmo님의 댓글의 댓글
@RaPo님에게 답글
답변 주셔서 정말정말 감사합니다. 어쩐지 휴대폰이랑 컴퓨터랑 일부러 동시에 물어봤더니 대기하다가 답을 주더라고요. 이런 이유였군요. 구글 젬마2 4비트 양자화 모델이 우리말을 얼마나 잘 알아듣고 잘할지는 모르겠습니다. 구글 젬마로도 한 번 실험해보고, 성능에서 큰 차이가 없으면 RaPo님 말씀처럼 프로세스를 두 개 만들어서 최소 두 명은 동시접속하여 쓸 수 있게 해보겠습니다. 덕분에 많이 배웠습니다. 자세히 알려주셔서 감사합니다!!!!!
kungmo님의 댓글의 댓글
@RaPo님에게 답글
구글 gemma 2 9B 의 GGUF 파일 gemma-2-9b-it-Q6_K_L.gguf 을 구해서 챗봇에 올렸습니다.
EEVE 10.8B Q8 과는 비교도 안 되게 정확하게 잘 대답합니다. 메모리는 EEVE Q8 모델보다 1GB 더 먹긴 하고, 답변 생성 속도가 조금 느리긴 하지만, 뭔가 조금 더 생각하고 정확하게 답하려고 노력하는 느낌이 듭니다.
그래서.. 동시접속은 할 수 없는 상태이지만, 성능이 정말 좋아서 놀랍습니다.
EEVE 10.8B Q8 과는 비교도 안 되게 정확하게 잘 대답합니다. 메모리는 EEVE Q8 모델보다 1GB 더 먹긴 하고, 답변 생성 속도가 조금 느리긴 하지만, 뭔가 조금 더 생각하고 정확하게 답하려고 노력하는 느낌이 듭니다.
그래서.. 동시접속은 할 수 없는 상태이지만, 성능이 정말 좋아서 놀랍습니다.
RaPo님의 댓글의 댓글
@kungmo님에게 답글
gemma 모델이 생각보다 괜찮습니다.
좀 더 도움이 되고자 하는 마음으로 한 번 더 설명 드리려고 하니 양해부탁드립니다.
IT 모델은 사이즈를 몰라서 제가 말씀드리기 어렵고, gemma2 모델 기준으로 파일 사이즈가 9b-Q4는 5.4GB, 9b-Q6은 7.6GB입니다. 메모리에 올리면 이것보다 사이즈가 조금 더 커지죠.
VRAM의 사양에 따라서, 양자화를 이용해 성능은 좀 떨어지지만, 메모리를 아낄 수 있는 방법을 사용하게 됩니다.
Q6 모델이 대략 9~10 정도 차지하는 것 같은데, Q2 모델을 만들어서 테스트 하는 방법도 있습니다.
아래 링크에서 허깅페이스 모델을 gguf로 변경해서 임포트하는 방법을 확인해보시고 구축해보길 권해봅니다.
https://github.com/ollama/ollama/blob/main/docs/import.md
여기까지 하신다면 올라마로 AI 서버 구축은 끝납니다.
고생 많이 하셨습니다.
좀 더 도움이 되고자 하는 마음으로 한 번 더 설명 드리려고 하니 양해부탁드립니다.
IT 모델은 사이즈를 몰라서 제가 말씀드리기 어렵고, gemma2 모델 기준으로 파일 사이즈가 9b-Q4는 5.4GB, 9b-Q6은 7.6GB입니다. 메모리에 올리면 이것보다 사이즈가 조금 더 커지죠.
VRAM의 사양에 따라서, 양자화를 이용해 성능은 좀 떨어지지만, 메모리를 아낄 수 있는 방법을 사용하게 됩니다.
Q6 모델이 대략 9~10 정도 차지하는 것 같은데, Q2 모델을 만들어서 테스트 하는 방법도 있습니다.
아래 링크에서 허깅페이스 모델을 gguf로 변경해서 임포트하는 방법을 확인해보시고 구축해보길 권해봅니다.
https://github.com/ollama/ollama/blob/main/docs/import.md
여기까지 하신다면 올라마로 AI 서버 구축은 끝납니다.
고생 많이 하셨습니다.
kungmo님의 댓글의 댓글
@RaPo님에게 답글
RaPo 님 덕에 gemma2 모델을 쓰고 있는데 이렇게 좋은 게 오픈소스로 공개되어서 누구나 쓸 수 있다는 점에 계속 감탄 중입니다.
GGUF 파일은 https://huggingface.co/bartowski/gemma-2-9b-it-GGUF 에서 이미 Q2 모델까지 종류별로 다 변경해두셔서 제가 만들지 않아도 될 것 같습니다. 그런데.. 걱정은.... 학생이 답변을 받을 때 속도도 좋지만, 모델이 이상한 소리를 할까봐 걱정입니다.
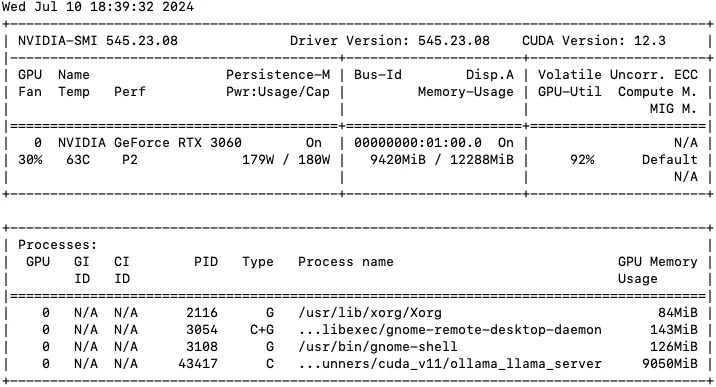
이 모델이 한창 돌아갈 때면 총 메모리 사용량이 9 GB가 조금 넘어갑니다. 사람들 많이 안 쓸 때 테스트 삼아 Q2 모델로 적어도 두 명은 동시 접속할 수 있도록 해보겠습니다. 찾아보니 VLLM을 쓰면 동시접속이 가능하게끔 해 주는 것 같기도 합니다. 할 일이 많은 것 같습니다. ㅎㅎ 매번 답변 주셔서 정말 감사합니다!
GGUF 파일은 https://huggingface.co/bartowski/gemma-2-9b-it-GGUF 에서 이미 Q2 모델까지 종류별로 다 변경해두셔서 제가 만들지 않아도 될 것 같습니다. 그런데.. 걱정은.... 학생이 답변을 받을 때 속도도 좋지만, 모델이 이상한 소리를 할까봐 걱정입니다.

이 모델이 한창 돌아갈 때면 총 메모리 사용량이 9 GB가 조금 넘어갑니다. 사람들 많이 안 쓸 때 테스트 삼아 Q2 모델로 적어도 두 명은 동시 접속할 수 있도록 해보겠습니다. 찾아보니 VLLM을 쓰면 동시접속이 가능하게끔 해 주는 것 같기도 합니다. 할 일이 많은 것 같습니다. ㅎㅎ 매번 답변 주셔서 정말 감사합니다!
kungmo님의 댓글의 댓글
@RaPo님에게 답글
그리고 Streamlit 을 썼는데, 얘는 이상하게 LangChain에서 memory 기능이 동작을 안 해서 3일을 고생하다가, 결국 Chainlit으로 갈아탔습니다. 그래서 주소도 http://acer2.snu.ac.kr:8501 로 옮겼습니다. Streamlit이 더 예쁘긴 한데, Chainlit은 랭체인에 맞게 만들었는지 기능성은 더 좋은 것 같기도 하고... 그렇습니다. ㅎㅎ 감사합니다.
plaintext님의 댓글


아예 다른 의미로 혼동하는 경우도 있고
답변 내용의 용어 일관성도 다소 부족할때가 있네요
그래도 재밌는 체험이었습니다.
현재는 사용자가 적은지 반응 속도 괜찮다고 느껴집니다
답변 내용의 용어 일관성도 다소 부족할때가 있네요
그래도 재밌는 체험이었습니다.
현재는 사용자가 적은지 반응 속도 괜찮다고 느껴집니다
kungmo님의 댓글의 댓글
@plaintext님에게 답글
써 주셔서 감사합니다! 소형 LLM에 RAG를 붙여서 이래저래 시도해도 성능이 여전히 부족합니다. 용어는 고등학교 통합과학을 벗어난 것이라면 엉뚱한 소리를 많이 할 것 같습니다. ㅠㅠ 그래도 재밌는 경험이었다고 하시니 계속 보완해서 쓸만하게 만들어보겠습니다.
브루스님의 댓글
저도 같은 방식으로 사내 규정 챗봇을 만들어 보려고 시도 중인데...
질의 응답 데이터셋 만들기가 쉽지가 않더라구요.
방금 들어가서 질문 하나 던져봤는데, 답변 잘 하더군요!