
![]() 심심해 (125.♡.200.205)
심심해 (125.♡.200.205)
2024년 10월 11일 AM 08:11 · 수정됨(10:50)

인텔 코어 울트라 200S 데스크탑 CPU 공식 발표: 애로우 레이크가 큰 효율성 향상을 약속하다.

오늘, 인텔의 애로우 레이크 프로세서가 마침내 등장했습니다.
이제 우리는 인텔 코어 CPU에 작별을 고하고, 인텔 코어 울트라 200S에 환영의 손을 흔들 때입니다. 이 데스크탑 라인업은 최근 인텔 모바일 CPU의 많은 아키텍처 개선을 전 세계의 데스크탑에 가져옵니다. 인텔은 CPU 성능과 전력 소비 모두에서 인상적인 향상을 약속하고 있습니다. 우리는 이 모든 것을 먼저 자세히 설명한 후, 구매 가능한 특정 SKU에 대해 이야기할 것입니다.

인텔 애로우 레이크 코어 울트라 200S 타일 및 패키징
미디어 레이크는 큰 칩을 기능 단위로 나누는 인텔의 디자인인 "타일"을 도입했습니다. 이는 패키지 기판 상에서 고속 인터커넥트를 사용하여 조립된 개별 실리콘 조각들입니다. 그러나 이러한 CPU는 데스크탑 시스템에 탑재되지 않았기 때문에 애로우 레이크는 이 타일 개념이 노트북에서 고성능 기계로 넘어오는 곳입니다. 아키텍처는 그러나 루나 레이크를 더 닮아 있으며, 조직적 및 성능 측면에서 많은 의미가 있습니다.
애로우 레이크의 타일은 목적에 따라 나누어져 있습니다. 컴퓨트 타일에는 E(효율) 및 P(성능) 코어의 모든 CPU 코어가 포함되어 있습니다. 인텔 코어 울트라 데스크탑 및 성능 노트북 CPU는 루나 레이크에서 약간 축소된 GPU 타일이 있으며, 이 PC는 별도의 GPU를 갖출 것으로 예상됩니다.

코어 울트라 200S 애로우 레이크 타일 기반 아키텍처
이전 미디어 레이크에서 낮은 전력의 E-코어를 포함했던 SoC 타일이 여전히 존재합니다. 그러나 이 타일은 GPU 외의 비디오 처리 및 기타 가벼운 작업을 위한 유틸리티 역할에 더 중점을 둡니다. 이 타일은 최대 4개의 4K 60Hz 디스플레이 및 비디오 인코딩/디코딩 블록의 출력 로직을 포함하고 있습니다. 인코딩과 디코딩을 위한 지원되는 비디오 코덱에는 AVC, HEVC, VP9, AV1을 위한 8k 10비트 HDR 인코딩이 포함됩니다.

코어 울트라 CPU의 타일 컬렉션은 그 빠른 인터커넥트로 묶이고, 인텔은 이와 함께 3D 포베로스 패키징을 사용하고 있습니다. 이는 이전에 미디어 레이크에서도 사용된 칩 스태킹 기술로, 다양한 종류의 로직을 최대 실리콘 공간 관리와 더 깊은 통합을 위해 보다 효율적으로 구성할 수 있게 해줍니다.
인텔 애로우 레이크 P-코어: 라이온 코브가 데스크탑에서 포효하다
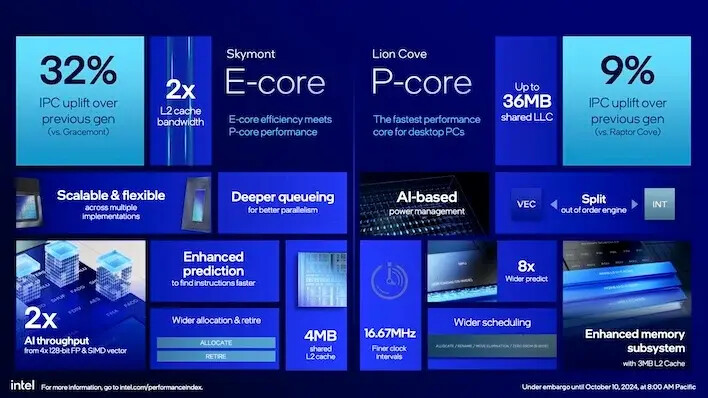
인텔은 라이온 코브 아키텍처 디자인에 있어 몇 가지 목표를 염두에 두었습니다. 우선, 라이온 코브는 최고의 단일 스레드 성능을 위한 와트당 성능 및 면적당 성능(제곱 밀리미터당)을 염두에 두고 설계되었습니다. 결과적으로 아키텍처는 IPC 및 향후 확장을 개선하기 위한 개편이 이루어졌습니다.
회사의 루나 레이크 모바일 CPU와 마찬가지로, 인텔의 라이온 코브 아키텍처는 코어 울트라 200 시리즈의 P-코어를 구동합니다. 이전 보도에서 언급된 내용은 지금도 여전히 사실입니다. 인텔의 대칭 멀티 스레딩(SMT) 기술인 하이퍼 스레딩은 이제 사라졌습니다. 인텔은 해당 기능을 구현하는 데 사용된 실리콘을 회수하고(여기에는 SMT 자체 외에 스케줄링 및 기타 지원 로직이 포함됨), 대신 최대한의 단일 스레드 성능에 집중하는 것이 더 낫다고 생각하고 있습니다.
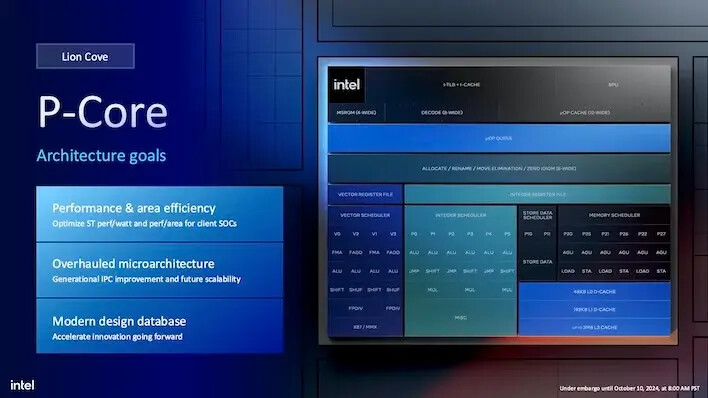
리소스 할당은 런어 레이크가 노트북에 탑재된 이후로 크게 변화하지 않았습니다. 여전히 18개의 실행 포트(즉, 기능 유닛)가 동일하고, "8배 더 넓은" 분기 예측 유닛과 레드우드 코브와 비교해 더 넓은 스케줄러가 있습니다. 그 특정 아키텍처는 데스크탑에서는 사용할 수 없었지만, 메테오 레이크의 일부로서 TDP 사양이 10와트 미만에서 28와트까지 다양한 노트북으로 출하되었습니다. 그러나 라이온 코브가 랩터 코브보다 상당히 더 병렬적이라는 것도 사실입니다. 이는 단일 스레드 성능 향상으로 이어져야 합니다.
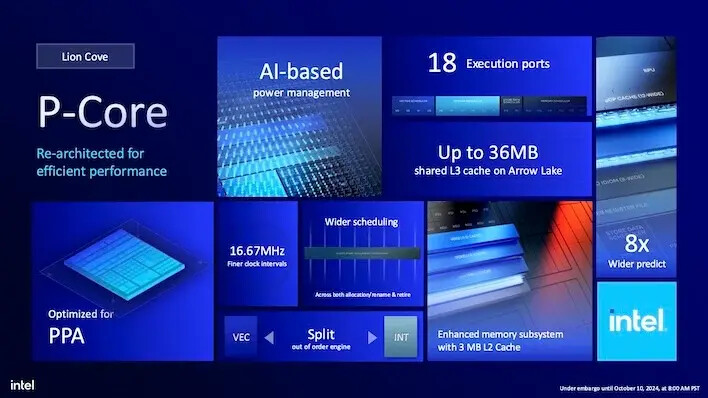
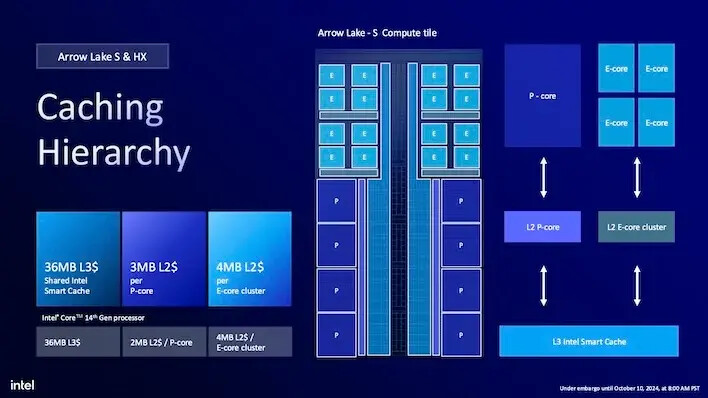
최근 몇 년간 인텔은 CPU에 많은 캐시를 부여하는 것이 습관이 되었지만, 애로 레이크는 이를 조금 더 강화했습니다. 우선, 14세대 CPU와 비교했을 때 L3 공유 스마트 캐시 크기는 코어 수에 따라 최대 36MB로 유지됩니다. E-코어 클러스터당 4MB의 L2 캐시도 마찬가지입니다. 그러나 각 P-코어는 L2 캐시가 50% 더 많아져 이전의 2MB에서 3MB로 증가하므로, 8개의 P-코어를 가진 CPU는 P-코어 그룹에 대해 L2 캐시가 16MB에서 24MB로 증가합니다.
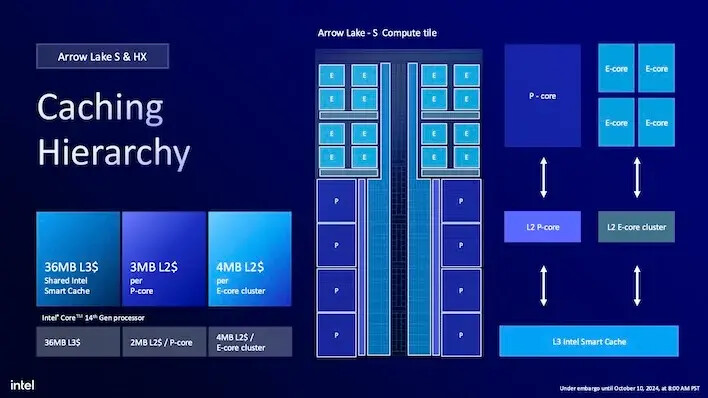
전반적으로 인텔은 라이온 코브 P-코어가 14세대 데스크탑 CPU의 랩터 코브 코어보다 약 9% 빠르다고 말합니다. 이는 시계 주파수 간 비교일 뿐이지만, 명목 시계 속도가 더 높다면 이 이점은 더욱 증가할 것입니다.
인텔 애로우 레이크 E-코어: 스카이몬트 효율성
앞에서 다룬 바와 같이, 우리는 E-코어의 목적이 변화했음을 지적했습니다. 인텔은 하이퍼스레딩을 제거했기 때문에 스케줄러는 변경할 수밖에 없었고, 인텔이 그렇게 하는 동안 설계팀은 처음에는 E-코어에서 모든 것을 스케줄링하는 것이 가장 좋겠다고 결정했습니다. E-코어는 전력을 덜 소모하고 열을 덜 발생시키기 때문입니다. 이것은 스케줄러의 주요 초점이 E-코어에 맞춰졌고, E-코어는 빠를 필요가 있었습니다. 그리고 스카이몬트에서, 바로 그와 같은 특성을 가지고 있습니다.

우리는 스카이몬트가 메테오 레이크의 크레스트몬트 코어보다 "넓은" 설계를 가지고 있다는 것을 이미 알고 있지만, 알더 레이크와 랩터 레이크 시기에 비해 그 말이 더욱 사실입니다. 그레이스몬트와 비교했을 때, 스카이몬트는 더 나은 병렬성을 위해 더 깊은 명령 큐잉을 가지고 있으며, 2.5MB에서 증가한 4MB의 공유 L2 캐시와 두 배의 캐시 대역폭을 가지고 있습니다.
인텔은 스카이몬트를 가장 효율적인 성능 아키텍처라고 부릅니다. 에너지 효율성을 유지하면서 성능을 희생하는 것이 아니라, 스카이몬트는 지속적인 부하가 필요하지 않은 작업의 주요 처리 유닛으로 충분히 강력합니다. 이는 P-코어를 유휴 상태로 유지하고 시스템 전력 요구 사항을 낮춥니다.

이 모든 것이 인텔의 14세대 CPU의 E-코어에 비해 데스크탑 성능에서 큰 이점을 가져옵니다. 종합적으로 회사는 단일 스레드 INT 성능에서 약 32% 증가한 IPC를 기대해야 한다고 말합니다. 이 32%는 다중 스레드 INT 성능에서도 동일하게 유지됩니다. 이는 클럭 속도의 차이를 고려하지 않고도 시계당 훨씬 더 빠릅니다.
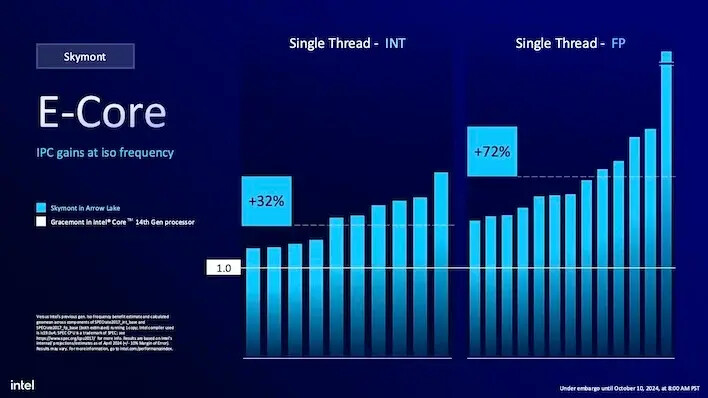
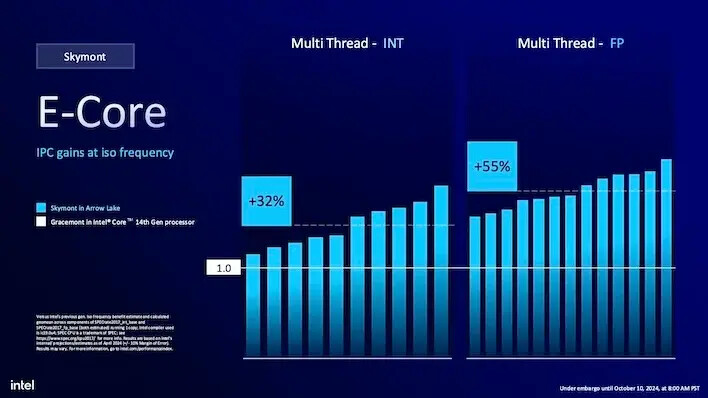
애로우 레이크의 부동 소수점 성능 또한 더욱 향상되어 단일 스레드 작업에서 그레이스몬트보다 최대 72% 더 빠릅니다. 다중 스레드 부동 소수점 성능은 약 55%로 약간 떨어지지만, 이는 동일한 주파수에서의 IPC 증가가 아닌 기대할 수 있는 총합입니다. 스카이몬트는 E-코어를 배경에서 주요 퍼포머로 끌어올렸습니다.
인텔 애로우 레이크 스레딩, 전력 관리, 코어 울트라 200S 프로세서 모델 및 성능 주장

애로우 레이크의 스레드 디렉터와 전력 관리
루나 레이크에서 업데이트된 인텔 스레드 디렉터가 애로우 레이크에도 도입됩니다. 이전에 언급했듯이, 회사는 E코어를 최대한 바쁘게 유지하고 P코어는 필요할 때만 깨우고 싶어 합니다. 랩터 레이크에서는 덜 요구되는 작업을 P코어에서 E코어로 이전할 수 있었습니다. 미디어 레이크는 E코어를 더 바쁘게 유지하려는 방향으로 발전했지만, 먼저 작업을 E코어로 지시했습니다.
하지만 미디어 레이크의 처리 자원은 SoC와 컴퓨트 타일에 분산되어 있었습니다. 이것은 더 세분화된 전력 관리를 가능하게 했지만, 작업이 코어 계층을 이동하는 과정에서 추가적인 단계를 초래했습니다. 작업은 SoC 타일의 E코어에서 컴퓨트 타일의 E코어로 이동한 후, P코어로 전송되어야 했습니다.

애로우 레이크에서는 루나 레이크와 마찬가지로 이 작업 방식이 상당히 변화했습니다. 이제 모든 코어가 컴퓨트 타일에 있기 때문에 관리해야 할 논리가 훨씬 간단해졌습니다. 물론 이는 여전히 대형 단일 칩 설계였던 인텔의 14세대 코어 프로세서와는 큰 변화를 의미합니다. 지금의 주요 차이점은 코어들이 백그라운드 작업에만 국한되지 않고, 새로운 작업의 첫 번째 대상이 될 만큼 충분히 빠르다는 것입니다.
작업 부하의 큰 변화 때문에 인텔의 스레드 디렉터 스케줄러도 큰 변화를 겪었습니다. E코어가 언제 절박하게 요청할지를 기다리는 대신 (IPC 피드백), 새로운 하드웨어 기반 예측 엔진이 작업 부하를 E코어로 가야 할지 아니면 꼭 P코어로 가야 할지를 더 잘 분류할 수 있습니다.


이 예시에서 볼 수 있듯이, 작업이 E코어에서 시작되지만 지속적인 부하로 인해 빠르게 P코어로 이동해야 할 때가 있습니다. 바로 그 지점에서 큰 코어가 개입해야 하며, 스레드 디렉터는 이를 매끄럽게 처리합니다.
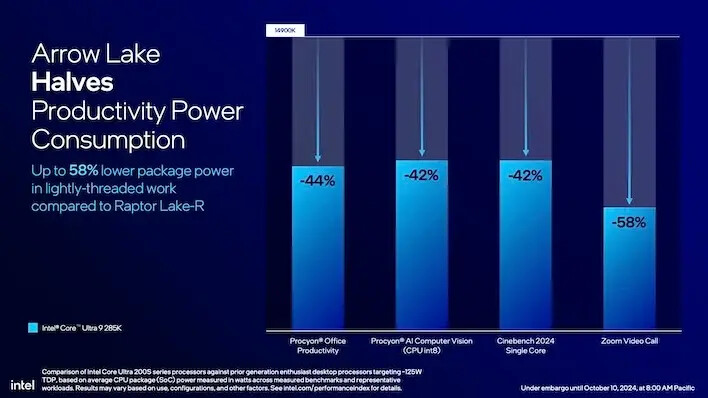
결론적으로 인텔에 따르면, 애로우 레이크는 경량 스레드 작업에서 최대 58%의 전력 소비 절감을 이룰 것이라고 합니다. 특히, 이는 이전 챔피언인 코어 i9-14900K와 비교하여 최상급 코어 울트라 9 285K에서 나타납니다. 전체 가정의 전기 요금에 큰 차이를 만들지는 않겠지만, 최신 GPU인 지포스 RTX 5090 같은 제품이 추가 전기를 소모하게 된다면, 어느 정도의 전력 절감은 환영할 만합니다.
인텔 코어 울트라 200S CPU 상세 정보
물론, 당신이 여기 온 이유는 잘 알고 있습니다. 80년대 어린 시절처럼 하드웨어에 반해볼 시간입니다. 이제는 시어스 홀리데이 카탈로그 대신 슬라이드 데크가 있습니다. 여기 그들이 화려한 모습으로 나타났습니다.

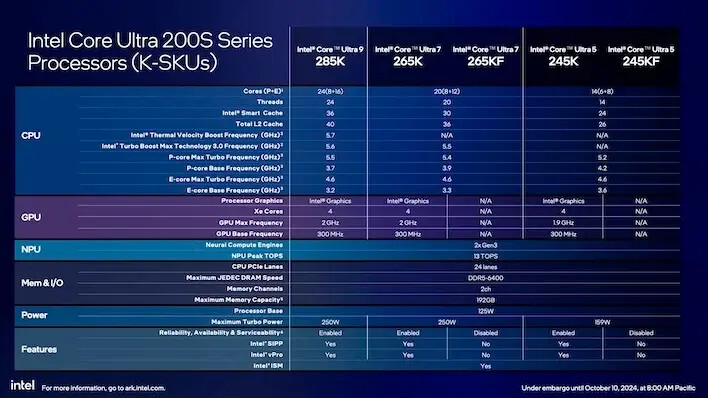
앞선 세대와 마찬가지로 CPU는 숫자로 나뉘어 있습니다: 코어 울트라 9, 울트라 7, 울트라 5, 각 단계마다 P-코어와 C-변형 코어 수에 따라 서로 다른 구성이 있습니다. 코어 울트라 9 285K는 8개의 P-코어와 16개의 E-코어로 총 24개의 하드웨어 스레드를 자랑하며 가장 높은 자리에 있습니다. 하이퍼 스레딩은 더 이상 없습니다. 이 CPU의 최고 클럭은 5.7 GHz로, 코어 i9-14900KS의 6.2 GHz보다 낮아졌습니다. 그럼에도 불구하고 아키텍처 개선 덕분에 코어 울트라 9 285K가 이전 세대 챔피언을 거의 모든 면에서 이길 것이라고 예상합니다.
전통적으로 인텔은 두 가지 모델 타입을 제공합니다. K로 끝나는 CPU는 각 범위의 최상위 모델입니다. 이 칩들은 기능적인 GPU 타일도 가지고 있습니다. 반면 KF로 끝나는 모델은 GPU 코어가 없습니다. 잠시 후 볼 수 있듯이, 이 칩들은 K 모델보다 조금 저렴하지만, 가격 차이는 크지 않습니다. GPU는 코어가 4개인 다소 느린 원래 Xe 그래픽 디자인을 사용하지만, 인텔은 열광적인 사용자들이 어차피 독립 GPU를 선호할 것이라고 기대합니다.

가격 대비 성능 최고는 코어 울트라 7 265K와 KF 모델이 될 것입니다. 이 CPU는 4개의 E-코어를 줄였지만 8개의 P-코어는 유지합니다. 또한 최고 클럭은 조금 더 낮은 5.5 GHz입니다. 한편, 코어 울트라 5 245K는 2개의 P-코어와 4개의 E-코어를 줄여 총 14개의 스레드를 가지고 있습니다. 최고 클럭은 약간 낮은 5.2 GHz입니다.
NPU가 데스크톱으로 – 애로우 레이크
이 프로세서 중 모든 것이 GPU는 아니지만, 모두 신경 처리 장치(NPU)를 가지고 있습니다. 이 장치는 대부분의 기계 학습 모델에서 발견되는 저정밀 수학에 탁월하며, LLM, 이미지 생성 또는 (이 경우 더 가능성이 높은) 경량 비디오 및 오디오 처리와 같은 작업을 가속화할 수 있습니다. 메테어 레이크 NPU와 유사하게 이 장치는 초당 조작 수(TOPS)에서 13의 성능을 기록합니다. 이는 마이크로소프트 팀즈나 윈도우 스튜디오 효과와 같은 애플리케이션에서 사용할 수 있는 라이브 번역/문서화 또는 비디오 배경 흐림과 같은 작업에 여전히 적합할 것입니다.

그러나 코어 울트라 200 시리즈 CPU의 루나 레이크를 떠올려 보면, 이 NPU는 다소 약해 보입니다. 모바일 버전의 48 TOPS에 비해 13 TOPS입니다. 이제 코어 울트라 시리즈에서 NPU가 존재한다는 것은 데스크톱 CPU에서 처음 있는 일입니다. 인텔과 AMD는 NPU를 출하했지만, 노트북 SKU에서만 그랬습니다. 여전히 NPU는 상대적으로 가벼운 AI 부하를 처리하는 용도로 존재하여 CPU와 GPU 엔진에서 오프로드할 필요가 없고, 자원을 더 나은 동시 처리를 위해 확보합니다.

물론 현실은, 데스크톱(그리고 HX 기반 노트북)의 경우에는 얇고 가벼운 노트북이 처리하는 것보다 훨씬 빠른 AI 프로세서인 독립 GPU도 있다는 것입니다. 물론, NVIDIA는 AI 공간에서 괴물이 되었습니다. 왜냐하면 그들의 GPU 칩이 AI에 필요한 수학을 정말 잘 수행하기 때문입니다. AMD도 AI 부문에서 부족하지 않으며, RDNA3 GPU는 기계 학습에 적합한 많은 메모리를 가지고 있으며, 자체 AI 가속기를 내장하고 있습니다. 따라서 많은 AI 가속이 얇고 가벼운 노트북 시장에서는 필수적이지 않다고 생각할 수 있습니다.

가격 관점에서 코어 울트라 200S 프로세서는 이전 세대와 크게 다르지 않습니다. 코어 울트라 285K는 코어 i9-14900K가 출시할 당시와 동일한 589달러입니다. 코어 울트라 7 265K는 가격을 33% 낮춰 거의 400달러 아래로 떨어졌습니다. 최상위 모델과 비교해 상대적으로 비슷하기 때문에 확실히 가격 대비 가치가 있는 목표입니다. 코어 울트라 5 245K와 KF는 이전 세대와 동일하게 300달러이지만, 스레드 수는 상당히 줄어들었습니다. 이는 훌륭한 거래를 나타내는지는 확실하지 않지만, 궁극적으로 테스트가 이를 결정할 것입니다.
인텔 코어 울트라 9 285K 애로우 레이크 성능 주장은 인상적
인텔은 14세대와 비교해 전력 소비가 크게 줄어들었을 뿐만 아니라, 새로운 코어 울트라 9 285K가 더 빠르다고 주장합니다. 인텔의 내부 벤치마크의 기하 평균은 코어 i9-14900K에 비해 15% 개선되었음을 보여주었습니다. 인텔은 또한 Ryzen 9 9950X(16개의 Zen 5 코어와 SMT를 통한 32스레드)와 비교해 13% 더 빠른 기하 평균을 가지고 있다고 말합니다.
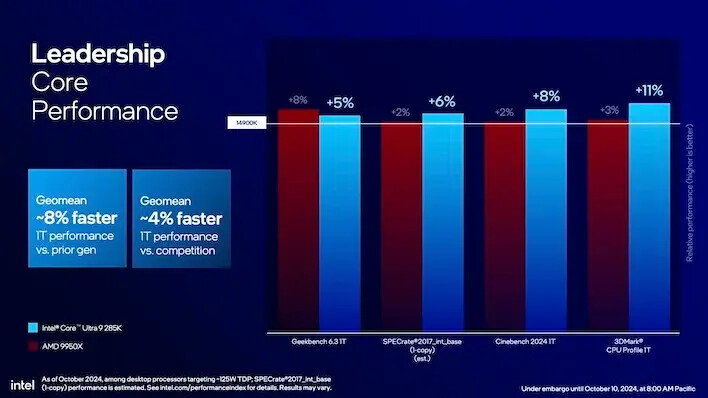
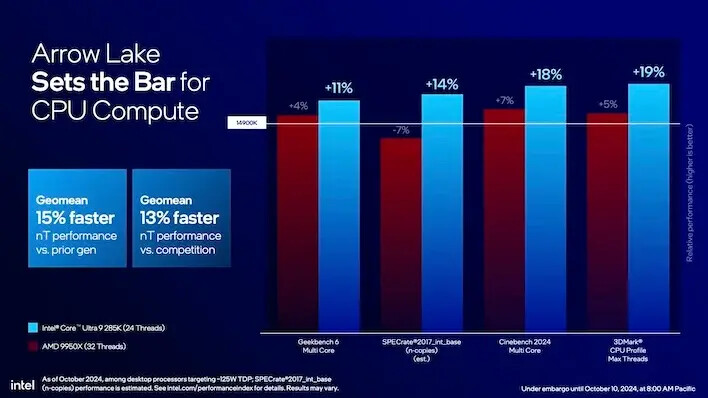
그 증가폭은 상대적으로 적은 수치지만, 실제로 이 이야기는 AMD의 Zen 5 아키텍처 기반 9000 시리즈 데스크탑 CPU와 매우 유사하게 들립니다. 이 CPU들은 전력 소비가 적으면서도 이전 세대보다 약간 더 빨랐지만, 많은 열성 팬들이 그 때문에 AMD를 비판했습니다.
인텔의 마지막 세대 CPU는 최근의 마이크로코드 업데이트가 있기 전까지 고장 문제를 겪었고, 일부 AMD 칩은 이상한 65W TDP를 가지고 있었습니다. AMD는 AGESA 업데이트를 통해 일부 칩의 기본 TDP를 높여 성능을 향상시키기로 결정했습니다. 인텔의 내부 벤치마크에 따르면, AMD의 라이젠 9000 시리즈는 앞으로 모든 성능이 필요할 것 같습니다.
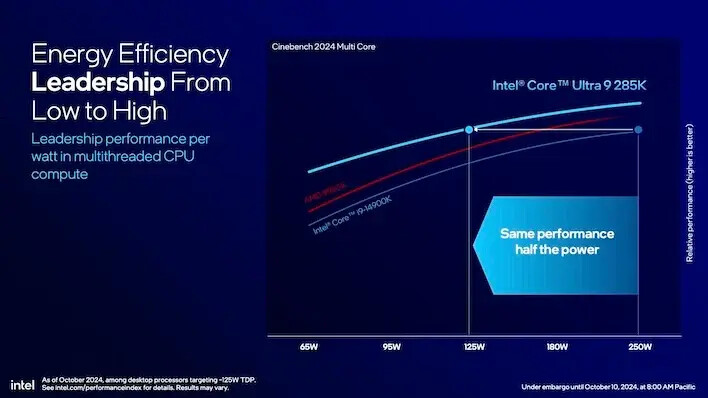
그게 충분하지 않다면, 인텔은 Core Ultra 9 285K의 성능이 Core i9-14900K와 동일하지만 전력 소모는 절반이라고 말합니다. 인텔의 기준으로도 AMD의 라이젠 9 9950X보다 상당한 차이로 앞서 있습니다.
결국, 이들은 1차 성능 주장일 뿐이며 실제 증거는 우리가 Core Ultra 200S를 직접 사용해봐야 알 수 있습니다. 이 흥미로운 새로운 데스크탑 칩들은 곧 만나볼 수 있을 것이며, 판매와 예약 주문은 오늘로부터 2주 후인 10월 24일부터 시작됩니다. HotHardware에서 우리의 독립적인 벤치마크를 위해 계속 지켜봐 주세요. 우리는 테스트 벤치에서 Arrow Lake를 곧 점화할 예정이며, 이 새로운 칩들이 어디에 위치할지 기대하고 있습니다.
댓글 (1)
-
 셀
셀셀빅아이

24.10.11 · 125.♡.200.218
댓글을 작성하려면 이 필요합니다.
그러나 지난 세대처럼 성능논란에 자유로울지 모르겠네요.