MS에서 놀라운 논문이 나왔습니다. ( from 김성완 )

W
![]() wind (211.♡.99.61)
wind (211.♡.99.61)
2025년 1월 10일 PM 01:45 · 수정됨(14:25)
조회 3,556 공감 0

마이크로소프트에서 놀라운 논문이 나왔습니다.
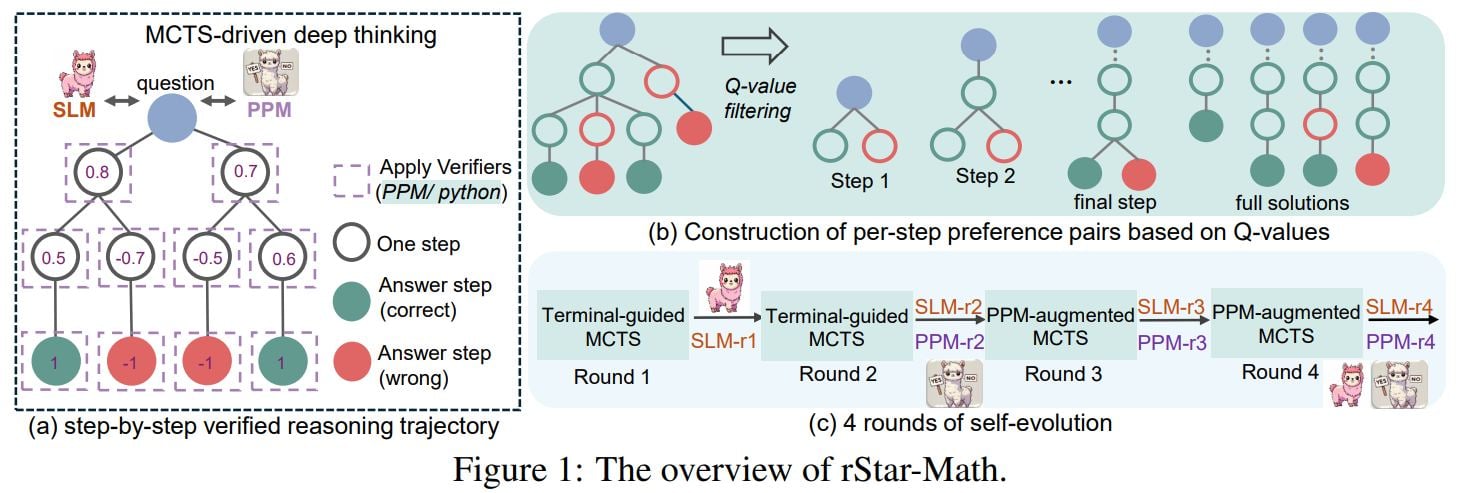
1.5B~7B에 불과한 작은 모델로 OpenAI의 o1에 필적하는 수학적 추론 능력을 달성했답니다.
제목: rStar-Math: 작은 언어 모델의 수학적 추론 능력 향상을 위한 자체 진화형 딥 씽킹
핵심 내용:
1. 주요 성과:
- 작은 규모(1.5B-7B)의 언어 모델로도 OpenAI의 o1과 비슷하거나 더 나은 수학 추론 능력 달성
- 상위 모델로부터의 지식 증류 없이 자체적인 진화 방식 사용
- MATH 벤치마크에서 Qwen2.5-Math-7B를 58.8%에서 90.0%로 향상
2. 주요 혁신:
- 코드 기반 CoT(Chain of Thought) 데이터 합성 방법 도입
- 새로운 프로세스 보상 모델 학습 방법 개발
- 4단계 자체 진화 레시피 구현
3. 핵심 방법론:
- Monte Carlo Tree Search(MCTS) 활용한 딥 씽킹 구현
- 단계별 검증된 추론 궤적 생성
- 프로세스 선호도 모델(PPM) 도입
4. 주요 발견:
- 내재적 자기 반성 능력의 출현
- PPM이 정리 적용 단계를 효과적으로 식별
- 보상 모델이 System 2 추론의 성능 상한을 결정
5. 실험 결과:
- MATH, AIME 2024, AMC 2023 등 다양한 벤치마크에서 우수한 성능 달성
- AIME 2024에서 평균 53.3%(15문제 중 8문제) 해결
- 상위 20% 고교생 수학 실력 수준 달성
6. 의의:
- 작은 언어 모델로도 고수준의 수학 추론 가능성 입증
- 자체 진화 방식을 통한 효율적인 성능 향상 방법 제시
- 수학 교육 및 AI 추론 연구에 새로운 방향 제시
이 연구는 작은 규모의 언어 모델도 적절한 방법론을 통해 복잡한 수학적 추론이 가능함을 보여주었으며, 향후 AI의 수학적 추론 능력 향상 연구에 중요한 통찰을 제공했습니다.
... 라고 합니다... 댓글에서 전문가 님들께서... 자세한 설명은... 쿨럭...
감사합니다...
댓글 (12)
-
 음
음음악매거진편집좀

25.01.10 · 39.♡.58.98
내재적 자기 반성 능력의 출현....건드리지 말아야할 것을 건드린거 아닐까요 -
 I
IImsomad
25.01.10 · 218.♡.93.116
완벽히 이해했어 짤이 필요합니다 -
 H
Hhappysinja
25.01.10 · 1.♡.222.2
로봇이 자체 진화 가능하다는??? 진짜 나중에 로봇이 인간을 지배할 수도~~~~ -
 버
버버즈라이터
25.01.10 · 172.♡.52.230
나중 되면 정말로 인간들은 일을 안하고 놀고만 있을 지도모르겠습니다
언능 재미있게 노는 방법을 찾아야 겠어요 - 외
외국인노동자입니다
→ 버즈라이터 25.01.10 · 157.♡.92.86
인간이 일하고 로봇이 놀수도 있습니다 - 떡
떡갈나무
25.01.10 · 1.♡.2.244
- 내재적 자기 반성 능력의 출현
와~ 엄청 빠르게 발전 하네요. -
 무
무무지개왕국
25.01.10 · 175.♡.78.96
으앙....스카이넷임 충성 충성!! -
 국
국국수나냉면
25.01.10 · 118.♡.93.189
와이프가 한분 더 생기는군요 . 잘 했어? 잘못했어? -
 D
DDev조무사
25.01.10 · 106.♡.249.210
어쩐지... (전혀 이해 못함) -
 윰
윰윰어
25.01.10 · 223.♡.56.80
내재적 자기반성이라고 하면
단순히 가중치나 점수를 더 받았던 쪽의 길로 선택을 수정해 나가는게 아니라
실패한 선택을 되돌아보고 실패를 답습하지 않도록 더 나은 선택을 하는 능력이 발현 되었다는 건가요 ㄷㄷㄷ
AI도 반성하는데 2찍 인간들은 반성 안하고..ㅠ
AI도 처음엔 반성했는데, 더 발달해서는 자기반성 없이 싸이코패스 일당독재같은 원AI 유니버스를 만들까?하고 오후 업무간 망상 해보게 되네요.
댓글을 작성하려면 이 필요합니다.