
![]() 심심해 (125.♡.200.205)
심심해 (125.♡.200.205)
2024년 6월 5일 PM 05:29 · 수정됨(06. 10. 09:33)

번역기(DeepL)로 인한 오역이 있을 수 있습니다.
인텔 루나 레이크 CPU 심층 분석: Chipzilla의 모바일 Moonshot
인텔 루나 레이크 심층 분석: 인텔은 완전한 프로세서 점검으로 반격합니다.

오랫동안 노트북을 구입하면 거의 확실하게 인텔 프로세서를 구입하는 경우가 많았습니다. 물론 AMD도 있었고 Macbook도 항상 존재했지만, 둘 다 오랫동안 시장의 반대편에 있는 틈새 제품이었습니다. 압도적인 대다수의 사용자에게는 인텔만이 노트북을 합리적으로 만들 수 있는 성능과 효율성의 매력적인 조합을 제공했지만, 최근 중요한 노트북 시장에서 인텔의 지배력이 공격받고 있습니다.
먼저, Apple은 놀라운 효율성을 제공하는 자체 개발 실리콘을 선보이며 인텔로부터 극적으로 탈피했고, 라이벌 AMD는 킬러 x86 성능과 강력한 그래픽 하드웨어를 제공하는 Ryzen SoC를 선보이며 급부상했습니다. 가장 최근에는 퀄컴이 엄청난 효율을 자랑하는 자체 개발 스냅드래곤 X 엘리트 프로세서를 선보였습니다. 인텔은 하이엔드 게이밍 노트북 시장을 대부분 장악하고 있지만, 칩질라는 중요한 '얇고 가벼운' 시장에서 치열한 경쟁을 벌이고 있습니다.

이에 대한 반격으로 이제 새로운 루나 레이크 프로세서가 출시되었습니다. 슬림하고 간결한 루나 레이크는 인텔의 여러 축에서 패러다임의 전환을 의미합니다. 고성능 제품에서 축소된 것이 아니라 얇고 가벼운 노트북 시장을 위해 특별히 제작된 루나 레이크는 경쟁사들과 정면으로 맞서기 위한 인텔의 최선의 노력의 결과물입니다.

루나 레이크는 효율성에 관한 모든 것
https://youtu.be/yLAf_xHoQ8U
이번 게임의 핵심은 효율성입니다. 많은 사람들이 전력 효율성과 관련하여 x86(-64)의 한계에 대해 언급했지만, 루나 레이크는 이 모든 것을 잠재울 수 있는 제품입니다. Microsoft는 "아마 이만한 x86 전력 특성을 본 적이 없을 것"이라고 말하며, 실제로 이 부품은 Microsoft Teams 회의 중 전력 소비 측면에서 AMD의 Ryzen 7 7840U와 Qualcomm의 Snapdragon 8cx Gen 3을 각각 30%와 20% 낮춘다고 주장합니다. 인상적인 내용입니다.

Meteor Lake에서는 타일로의 전환에 중점을 두었고 IP에 대한 수정이 거의 없었던 반면, Lunar Lake 패키지에는 모든 부분에 새로운 엔지니어링이 적용되었습니다. 온-패키지 LPDDR5X 메모리로의 전환, 긴밀하게 최적화된 Lion Cove P-코어, 근본적으로 수정된 Skymont E-코어, Xe2 그래픽 프로세서, 4세대 NPU, 심지어 스레드 스케줄링 및 열 모니터링 하드웨어의 주요 개선에 이르기까지 경쟁사에 대한 진정한 인텔의 풀 코트 압박이 이루어지고 있습니다.

다음 페이지에서 새로운 코어, 새로운 GPU 하드웨어, 새로운 NPU 실리콘에 대해 자세히 설명할 예정이지만, 먼저 이 새로운 SoC의 구성과 패키징 방식에 대해 잠시 이야기해 보겠습니다. 위의 슬라이드에서 볼 수 있듯이 루나 레이크는 7개의 부품으로 구성되어 있습니다. 작업의 핵심은 모든 처리 요소를 포함하는 컴퓨팅 타일에서 이루어지며, 플랫폼 컨트롤러 타일은 본질적으로 구식 "노스브리지"와 유사합니다. 이 타일은 I/O 및 기타 시스템 기능을 제공합니다. 컴퓨팅 타일은 TSMC의 N3B 공정에서 제작되며, 플랫폼 컨트롤러 타일은 TSMC N6에서 제작됩니다.

인텔이 루나 레이크 프로세서를 빌드하는 방법
이 모든 것은 Foveros 링키지를 통해 연결된 베이스 타일 위에 놓여 있으며, 이 타일은 패키지 인터포저 위에 놓여 있고, 두 개의 LPDDR5X DRAM 패키지도 여기에 연결됩니다. 실제로 인텔은 Apple의 M 시리즈 프로세서와 마찬가지로 루나 레이크용 RAM을 온패키지로만 출시하고 있습니다. 사용 가능한 메모리 구성에는 최대 8,533MT/s의 속도와 16 및 32기가바이트 용량이 포함되며, 이는 Meteor Lake의 최대 구성인 7,467MT/s에서 크게 향상된 속도입니다.

물론 인텔이 메모리를 온패키지로 전환하기로 결정한 이유는 향상된 전송 속도 때문만은 아닙니다. 메모리 인터페이스에서 소비되는 전력을 최대 40%까지 줄이고 시스템 마더보드의 복잡성과 물리적 면적을 획기적으로 줄일 수 있기 때문입니다. 이러한 변화의 유일한 단점이자 큰 단점은 RAM을 수리하거나 업그레이드할 수 없다는 것입니다. Lunar Lake 노트북의 RAM이 고장 나면 마더보드 전체를 교체해야 한다는 것입니다. 적어도 최종 사용자 입장에서는 납땜된 메모리가 고장 났을 때와 크게 다르지 않습니다.
루나 레이크의 기능 요소 다이어그램.
물리적 구조를 제외하면, 루나 레이크는 표면적으로 다른 최신 인텔 프로세서와 매우 흡사합니다. 4개의 "코브" P코어, 4개의 "몬트" E코어, 8개의 Xe 코어를 갖춘 Xe2 GPU, 전용 NPU, PCIe 5.0, Thunderbolt 4, 통합 Wi-Fi 7 등이 있습니다. 하지만 다음 페이지에서 살펴보겠지만, 인텔에게 루나 레이크는 결코 평범하지 않습니다. 라이언 코브 P 코어부터 시작하겠습니다.
인텔 루나 레이크 심층 분석: 최고의 성능을 위한 라이온 코브 P-코어
라이온 코브는 이름에서 알 수 있듯이 유성 호수에서 구현된 레드우드 코브의 후속 버전입니다. 레드우드 코브는 랩터 레이크에서 구현된 랩터 코브에 비해 약간의 업그레이드에 불과했지만, 라이온 코브는 극적인 변화입니다. 인텔의 말을 빌리자면, "제품 성능에 직접적으로 기여하지 않는 트랜지스터를 설계에서 제거하는 것"이 목표였습니다. 인텔은 루나 레이크가 제공한 기회를 통해 한동안 '코브' 계보에 존재했던 "마이크로 아키텍처 장애물을 근본적으로 해결"할 수 있었다고 말합니다.
루나레이크의 라이온 코브 P-코어 설명

이를 통해 인텔은 싱글 스레드 성능 및 면적 효율성, 향후 확장성을 제공하는 마이크로 아키텍처의 전면적인 개편, 향후 제품을 위해 보다 쉽게 설계를 반복할 수 있는 설계 데이터베이스의 현대화라는 세 가지 주요 목표를 달성하고자 했습니다. 이 세 가지 범주 각각에서 인텔의 변화를 살펴보겠습니다.
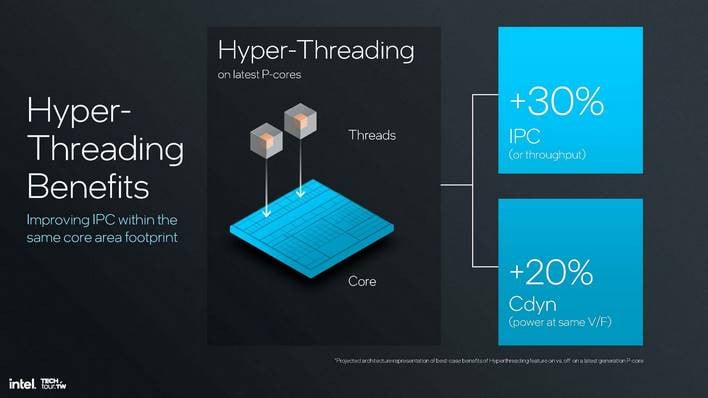
라이언 코브의 가장 큰 변화 중 하나는 소문대로 하이퍼스레딩이 제거되었다는 점입니다. 이 익숙한 기능은 펜티엄 4 HT와 함께 x86에 도입되었으며, 인텔은 스레드 수가 많은 환경에서도 하이퍼스레딩을 사용하면 동일한 전압과 주파수에서 20%의 전력으로 30%의 IPC 향상을 제공할 수 있다고 설명합니다. 이는 매우 확실한 이득이며, 결과적으로 하이퍼스레딩은 대형 P코어 전용 서버 부품에서 유용하게 사용될 것입니다.
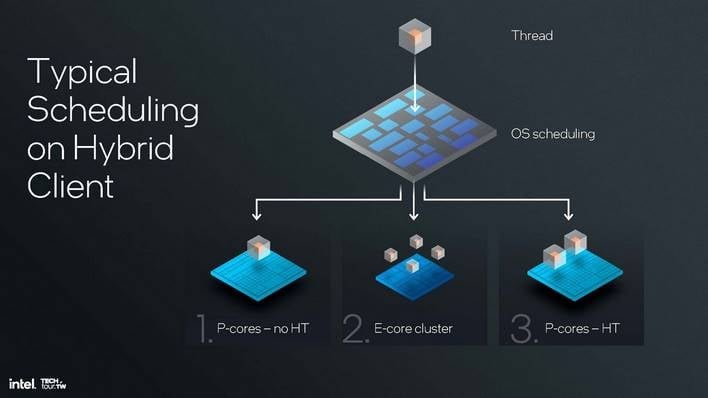
실제로 하이퍼스레딩의 매력을 떨어뜨리는 것은 E코어의 존재입니다. 작업 스케줄링 방식으로 인해 일반적으로 P코어의 하이퍼스레드를 사용하는 것보다 E코어에서 작업을 스케줄링하는 것이 더 효율적이고 훨씬 더 성능이 좋습니다. 이 때문에 인텔의 일반적인 스케줄링 패러다임은 P-코어를 먼저 채운 다음 E-코어를 사용하고 마지막으로 하이퍼스레드에서 작업을 스케줄링하는 것이었습니다. (이제 루나 레이크에서는 스케줄링 패러다임이 완전히 달라졌지만 이에 대해서는 나중에 설명하겠습니다.)

일반적으로 P코어당 하나의 스레드만 스케줄링하기 때문에 하이퍼스레딩에 낭비되는 실리콘 영역이 엄청나게 많습니다. 두 번째 스레드를 처리하기 위한 추가 로직이 필요할 뿐만 아니라 스레드 스케줄링 및 보안을 위한 지원 로직도 모두 포함되어 있습니다. 하이퍼스레딩을 제거함으로써 인텔은 P 코어를 훨씬 더 밀도 있고 효율적으로 만들 수 있었지만, 인텔은 여기서 멈추지 않았습니다.
라이언 코브는 적어도 루나 레이크에서 구현된 것처럼 회사의 트랜잭션 동기화 확장, 고급 매트릭스 확장 및 "다양한 기타 기능"에 대한 모든 실리콘 지원도 중단했습니다. 다시 한 번 강조하지만, 회사는 "설계에서 트랜지스터를 제거한다"는 패러다임에 대해 매우 진지했습니다. 단일 스레드 속도를 위해 P코어는 철저하게 제거되었습니다.

이러한 변화 외에도 인텔은 CPU 코어의 주파수 관리 기능에도 큰 변화를 주었습니다. 사전 설정된 정적 열 가드 밴드를 사용하는 대신 작업 부하, 열 솔루션, 주변 온도 등의 조건에 실시간으로 적응할 수 있는 'AI 셀프 튜닝 컨트롤러'를 탑재했습니다. 이를 통해 더 긴밀한 주파수 수렴이 가능하며, 100MHz에서 16.67MHz 간격으로 클럭 스케일링의 세분성이 증가하여 최종적으로 더 높은 지속 클럭 속도와 성능을 제공합니다.

마이크로 아키텍처 개편 측면에서 인텔은 프로세서의 설계를 대대적으로 변경하여 완전히 넓혔습니다. 분기 예측 블록은 레드우드 코브보다 "최대 8배 더 넓어졌으며", 이를 통해 분기 예측기가 앞서 실행되어 코드 라인을 미리 가져올 수 있게 되었습니다. 인텔은 이를 활용하기 위해 명령어 캐시 요청 대역폭을 3배로 늘리고, 명령어 페치 대역폭은 사이클당 128바이트로 두 배로 늘렸다고 말합니다.
한편, 디코딩 대역폭은 사이클당 6개의 명령어에서 8개의 명령어로 증가했으며, 마이크로 연산 캐시와 큐는 모두 크게 증가했습니다. 캐시는 4000개에서 5250개로, 큐는 144개에서 192개로 증가했습니다. 이 두 가지 변화는 모두 성능보다는 효율성 문제에서 비롯된 것입니다. 연산이 캐시에 있으면 가져오기/디코딩 로직의 전원을 켤 필요가 없으며, 마이크로 연산 대기열이 커지면 칩이 더 긴 코드 루프를 지원할 수 있습니다.

가장 큰 변화 중 하나는 아웃오더 엔진의 분할입니다. 인텔은 리네이머와 스케줄링을 전용 정수 도메인과 벡터 도메인으로 분리했습니다. 이를 통해 도메인별 워크로드에서 전력을 절약할 수 있지만, 실제 이점은 인텔이 향후 설계에서 전체 구조를 재조정하지 않고도 이러한 도메인을 수정할 수 있다는 것입니다.
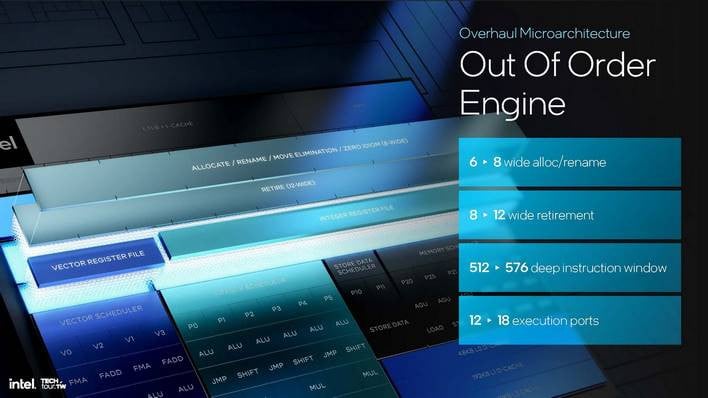


앞서 언급했듯이 Lion Cove에서는 전체 CPU 코어가 더 넓어졌습니다. 아웃오더 엔진은 전반적으로 25%에서 50%까지 더 넓어졌으며, 정수 도메인과 벡터 도메인 모두 용량이 증가했습니다. 특히 정수 블록은 이제 3개의 64비트 정수 곱셈을 동시에 수행할 수 있으며, 256비트 FP 디바이더의 수는 Redwood Cove에서는 1개에서 Lion Cove에서는 2개로 증가합니다. 또한 네 번째 SIMD ALU를 얻게 됩니다.
루나 레이크의 개선된 메모리 서브시스템

라이언 코브는 또한 프로세서의 캐시 계층구조를 대대적으로 재구성한 것이 특징입니다. 인텔은 평균 캐시 지연 시간을 줄이기 위해 CPU 코어의 이 부분을 "재설계"했다고 말합니다. 이를 위해 기존 L1 캐시는 이제 액세스 지연 시간이 20% 단축된 L0 캐시로 간주되며, 새로운 192K L1 캐시는 지연 시간 측면에서 L0과 L2 사이에 위치합니다. L2 캐시도 Redwood Cove에서 증가하여 Lunar Lake에서는 2.5MB로 확장되는 반면, Arrow Lake에서 구현된 Lion Cove는 전체 3MB의 L2 캐시를 갖게 될 것으로 보입니다.
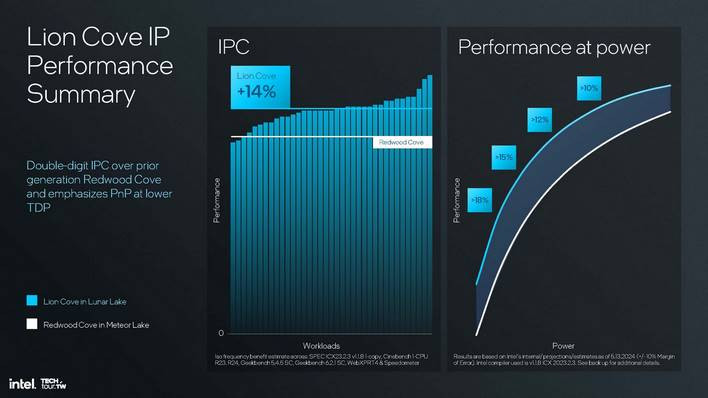
이 슬라이드는 적어도 자체 지표에 따르면, 클럭당 평균 14%의 성능 향상과 최저 전력 제한에서 레드우드 코브(Meteor Lake에서 구현됨)보다 18% 이상 더 나은 성능이라는 인텔의 노력의 결실을 보여줍니다. 더 높은 전력 수준에서는 성능 우위가 약간 떨어지지만, 루나 레이크의 전력 대역 최고치 근처에서도 두 자릿수를 유지합니다.
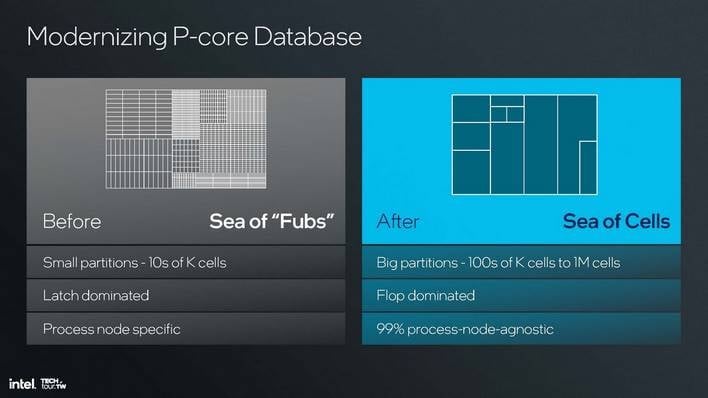
마지막으로, 라이언 코브에 적용된 인텔의 설계 철학의 변화를 확인할 수 있습니다. 왼쪽에는 손으로 그린 기능 블록, 즉 "퍼브"가 뒤섞여 있고, 오른쪽에는 인텔이 "수십만에서 수백만 개의 셀로 구성된 합성 기반 파티션"이라고 부르는 컬렉션이 있습니다.
간단히 말해, 설계에서 인위적인 물리적 경계를 줄임으로써 전력과 면적 측면에서 효율성이 향상되었다는 것입니다. 또한 "경화 시간"이 짧아져 인텔이 P 코어 설계를 반복하는 데 더 적은 시간이 필요하다는 것을 의미합니다. 실제로 루나 레이크의 '라이온 코브'는 올해 말 출시될 애로우 레이크에서 구현된 것과 이론적으로 동일한 CPU 코어와는 '몇 가지 측면'에서 분명히 다릅니다.
라이온 코브는 루나 레이크의 큰 변화 중 일부에 불과합니다. 인텔의 새로운 칩에 포함된 다른 x86 아키텍처에 대해 살펴보겠습니다: 스카이몬트.
인텔 루나 레이크 심층 분석: 최대 효율을 위한 스카이몬트 E-코어
라이온 코브가 레드우드 코브에서 급격한 방향 전환을 의미한다면, 스카이몬트는 완전히 지각 변동을 일으킬 수 있습니다. 루나 레이크의 근본적인 스케줄링 변경으로 인해 스카이몬트의 역할이 다소 바뀌었습니다. 저강도 백그라운드 작업을 위한 백업 프로세서가 아닌, 루나 레이크는 전력을 덜 사용하는 E코어에서 모든 것을 먼저 스케줄링하려고 시도합니다. 모든 것을 E-코어에서 스케줄링할 수 있다면 CPU의 고전력 부분, 즉 라이온 코브 CPU 코어와 대용량 12MB L3 캐시에 부하가 걸리는 것을 피할 수 있습니다.

라이온 코브와 마찬가지로 스카이몬트 개발 엔지니어들은 몇 가지 목표를 염두에 두고 있었습니다. 그중 가장 눈에 띄는 목표는 워크로드 범위를 늘리는 것이었습니다. 이는 E코어가 처리할 수 있는 작업의 양을 늘리는 것을 의미하며, 이는 크게 성능과 효율성 향상으로 귀결됩니다. 인텔의 엔지니어들은 미래 제품을 염두에 두고 Skymont의 AI 처리량을 두 배로 늘리고 전반적으로 확장성을 높이기 위해 노력했습니다.
성능과 효율성을 개선한 스카이몬트 E-Core

마이크로프로세서의 성능을 어떻게 향상시킬 수 있을까요? 조정할 수 있는 노브는 많지만 일반적으로 디자인 관점에서 가장 간단한 방법은 더 넓게 만드는 것입니다. 스카이몬트는 메테오 레이크의 크레스트몬트 E-코어보다 훨씬 더 넓습니다. 바로 앞부분부터 128바이트에 걸쳐 코드를 미리 가져올 수 있는 더 뛰어난 성능의 예측기를 갖추고 있으며 병렬 가져오기 기능이 50% 향상되었습니다.

이는 인텔이 프런트엔드에 세 번째 디코드 클러스터를 추가하여 스카이몬트에 3폭 디코드 클러스터 3개를 제공했기 때문입니다. 따라서 Skymont의 프론트 엔드는 Lion Cove의 프론트 엔드보다 훨씬 더 넓어졌습니다. 인텔은 또한 "공통 및 특정 마이크로코드 흐름"을 위한 마이크로 연산(micro-ops)을 생성할 수 있는 "나노코드"라는 새로운 기능을 구현했습니다. 이를 통해 디코더가 계속해서 병렬로 작업을 수행하여 대역폭을 추가하고 디코더 성능의 안정성을 향상시킬 수 있습니다. 마이크로 연산 대기열 용량도 96개 항목으로 50% 증가했습니다.

당연히 백엔드도 함께 성장했습니다. 할당/이름 변경은 이제 Crestmont보다 25% 더 넓어졌으며, 폐기 블록의 크기는 8개에서 16개로 두 배로 늘어났습니다. 인텔은 이것이 성능에 관한 것이 아니라 리소스 확보에 관한 것이며, 코어가 더 빨리 폐기할수록 더 많은 리소스를 확보할 수 있어 전력을 절약할 수 있다고 말합니다. 또한 인텔은 스카이몬트에서 종속성 차단을 구현하여 작업 결과가 이미 알려진 경우 코어가 종속성 체인을 "단락"시킬 수 있다고 말합니다. 이는 IPC를 개선합니다.
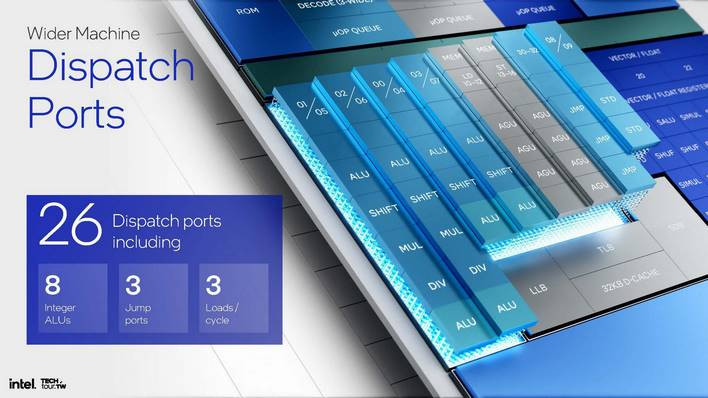
스카이몬트는 총 26개의 디스패치 포트를 제공합니다. 인텔은 하드웨어를 공유하거나 전용으로 만들 수 있다고 설명했습니다. 전자는 면적을 절약하고 후자는 전력을 절약합니다. 인텔은 전력상의 이유로 모든 것을 전용으로 만들기로 결정했기 때문에 스카이몬트의 디스패치 포트가 라이온 코브보다 8개 더 많습니다.

이러한 "더 넓게 만들기" 방법론은 특히 E코어의 부동소수점 유닛에 적용됩니다. 인텔은 128비트 벡터 유닛의 수를 두 배로 늘렸으며, 이는 크레스트몬트에 비해 이 코어의 피크 플롭스 또는 탑스를 두 배로 늘렸습니다. 인텔은 처리량이 크게 증가했음에도 불구하고 지연 시간도 줄였다고 말합니다. 이제 스카이몬트는 단 4사이클 만에 FMA 연산을 수행할 수 있습니다.
스카이몬트의 FP 유닛에 추가된 또 다른 주요 기능은 네이티브 부동 소수점 반올림 하드웨어입니다. 따라서 마이크로코드에서 비정규 지원 기능을 구현할 필요가 없습니다. 마지막으로, 크레스트몬트가 그레이스몬트에 비해 VNNI SIMUL 유닛 수를 두 배로 늘렸다면, 스카이몬트는 이를 다시 네 배로 늘렸습니다. 이렇게 하면 AI 계산 속도가 크게 빨라집니다.

메테오 레이크의 LP-E 코어가 2개의 코어에 2메가바이트의 L2 캐시를 사용했다면, 루나 레이크는 4개의 E 코어에 4메가바이트의 L2를 구현합니다. 인텔은 L2 캐시 대역폭을 두 배로 늘려 코어 수 확장을 개선했으며, 16바이트/클럭에서 32b/클럭으로 퇴거도 개선했다고 말합니다. 또한, 크레스트몬트와 이전 E-코어는 클러스터 내에서 코어 간에 데이터를 전송하기 위해 패브릭에서 바운스해야 했지만, 스카이몬트는 이제 L1에서 L1으로 직접 전송을 지원하여 협력 워크로드의 지연 시간을 개선합니다.

앞서 언급했듯이 이러한 변경의 목표는 CPU의 E-코어에서 가능한 한 많은 워크로드를 실행하는 것이었습니다. 이를 통해 루나 레이크 칩은 전력 소모가 많은 핫클럭 라이온 코브 코어의 전원을 낮게 유지하여 소중한 배터리 수명을 절약할 수 있습니다. 하지만 스카이몬트는 데스크톱 및 서버 CPU에도 적용될 예정입니다. 인텔은 두 가지 사용 사례에 대해 몇 가지 비교를 하고자 했습니다.
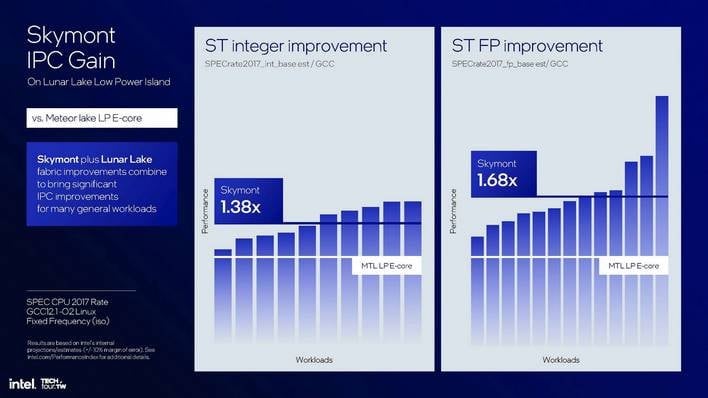
세대 간 대대적인 성능 향상을 제공하는 스카이몬트
여기에서는 루나 레이크의 스카이몬트 코어와 메테오 레이크 SoC 타일의 크레스트몬트 코어를 비교하고 있습니다. 이 테스트는 동일한 Linux 설정에서 동일한 컴파일된 바이너리를 고정된 주파수로 사용하므로 아키텍처별 최적화가 없는 순수한 IPC 측정입니다. 보시다시피, 회귀가 전혀 없을 뿐만 아니라 Skymont는 정수 및 특히 부동 소수점 연산 모두에서 절대적으로 엄청난 성능 향상을 제공합니다. 인텔은 FP 속도의 엄청난 향상은 주로 두 배로 향상된 벡터 하드웨어와 앞서 언급한 네이티브 하드웨어 비정규 반올림 지원 덕분이라고 말했습니다.
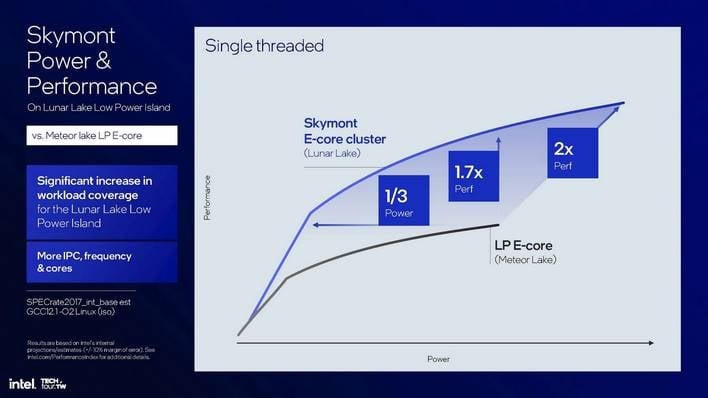
보시다시피, 인텔에 따르면 적어도 루나 레이크의 스카이몬트는 1/3의 전력으로 메테오 레이크 LP-E 코어와 동일한 성능을 달성하거나, 동일한 전력으로 약 70% 더 나은 성능을 낼 수 있습니다. 그러나 주목할 만한 점은 Meteor Lake의 전력 및 스케줄링 변경으로 인해 Skymont는 Meteor Lake의 Crestmont에 비해 Lunar Lake에서 훨씬 더 높은 클럭을 기록할 수 있다는 점입니다. 결과적으로 최고 속도는 코어당 성능이 약 두 배로 실제로 더 높습니다.
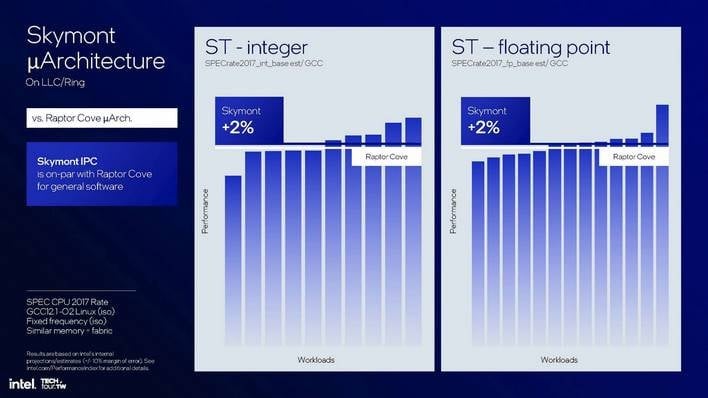
한편, 링 버스와 마지막 레벨 캐시를 나머지 CPU와 공유할 수 있는 데스크톱 또는 서버 프로세서에 구현된 스카이몬트의 경우, 평균적으로 랩터 코브와 거의 동등한 IPC를 달성할 수 있는 것으로 나타났습니다. 이는 실제로 놀라운 결과입니다. 스카이몬트는 여전히 매우 효율적인 E코어 설계이지만, 많은 워크로드에서 랩터 코브 P코어와 클럭 대 클럭으로 맞먹을 수 있습니다. 인텔은 이는 절충점이며 일부 항목에서는 여전히 랩터 코브의 IPC가 더 우수하다는 점을 지적합니다. 결국 두 제품은 매우 다른 CPU입니다. 하지만 근본적인 결론은 스카이몬트가 일상적인 작업에서 랩터 코브와 비슷한 성능을 제공할 수 있다는 점이며, 이는 매우 놀라운 일입니다.

두 CPU 코어에 대해 이야기했으니 이제 루나레이크 다이의 가장 큰 부분인 Xe2 통합 GPU에 대해 알아볼 차례입니다. 라이온 코브 P코어 및 스카이몬트 E코어와 마찬가지로, 루나 레이크 통합 GPU는 Meteor 레이크에서 대폭 수정되었으므로 다음 페이지에서 그 방법을 알아보시기 바랍니다.
인텔 루나 레이크 심층 분석: Xe2 배틀메이지 그래픽 엔진
솔직히 말씀드리자면, 1세대 인텔 Xe는 정말 대단했습니다. 아키텍처에 많은 변형이 있었고, 매우 다양한 제품에서 다양한 형태로 등장했습니다. 1세대 제품인 만큼 구현상의 어려움과 설계상의 문제도 있었습니다. 누구나 처음 사용할 때 겪는 일입니다.

인텔은 Xe2가 새로운 아키텍처이며, "LP" 또는 "HPG"와 같은 접미사 없이 그냥 Xe2라고 말합니다. 이 아키텍처는 루나 레이크에서 데뷔하지만, "배틀메이지"로 알려진 인텔의 차세대 외장형 GPU에도 탑재될 예정입니다. 인텔의 동료인 TAP는 루나 레이크의 IGP와 배틀메이지의 차이는 "아키텍처가 아닌 트랜지스터의 차이"라고 말했습니다.
루나레이크의 강력한 Xe2 배틀메이지 iGPU
개발자에 따르면 Xe2는 대부분의 워크로드에서 호환성과 활용도가 "극적으로 높다"고 합니다. 높은 활용도는 곧 높은 효율을 의미하며, 이는 당연히 오늘날 게임의 이름이기도 합니다. 아래 슬라이드는 기존 Xe 아키텍처와 비교하여 멀티플라이어가 적용된 Xe2의 다양한 마이크로 벤치마크를 보여줍니다. 보시다시피 모든 것이 개선되었지만 일부 항목은 다른 항목보다 훨씬 더 많이 개선되었습니다.
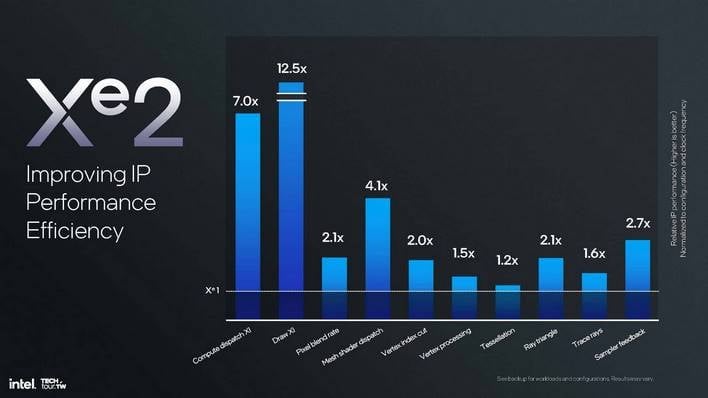
처음 두 개의 막대는 "컴퓨팅 디스패치 XI"와 "그리기 XI"입니다. 여기서 "XI"는 DirectX 12와 Vulkan의 핵심 기능인 "간접 실행"을 의미합니다. 자세한 설명은 생략하고, CPU가 모든 명령을 직접 실행하는 대신 모든 명령을 간접 버퍼에 일괄 처리한 다음 "ExecuteIndirect" 명령을 보내 GPU에 모든 작업을 수행하도록 지시하는 방식입니다.
간접 실행은 Direct3D 11.0부터 DirectX의 일부였지만, 원래 Xe 아키텍처는 하드웨어에서 이를 지원하지 않았기 때문에 드라이버에서 에뮬레이션해야 했습니다. 이것이 다양한 타이틀에서 Arc GPU의 성능이 일관되지 않은 가장 큰 이유 중 하나입니다. 위의 마이크로 벤치마크 결과에서 짐작할 수 있듯이 간접 실행은 Xe2에서 지원됩니다.

Xe2는 "매우 간단한 모듈식 아키텍처"로 설명됩니다. GPU는 하나 이상의 렌더 슬라이스로 나뉘며, 여기에는 지오메트리, 텍스처링, 래스터화 등을 처리하는 고정 기능 그래픽 하드웨어뿐만 아니라 3개 이상의 Xe 코어가 포함되어 있습니다. 루나 레이크에서 구현된 Xe2에는 각각 4개의 Xe 코어가 있는 2개의 렌더링 슬라이스가 있습니다.

이 다이어그램은 Lunar Lake용 통합 Xe2 GPU의 전체 레이아웃을 간략하게 보여줍니다. 8개의 Xe 코어와 각각 8개의 Xe 벡터 엔진이 있으며, Meteor Lake의 Xe-LPG 통합 GPU와 달리 XMX 매트릭스 연산 유닛이 하나씩 포함되어 있습니다. 또한 각 Xe 코어는 레이 트레이싱 유닛과 짝을 이루며, 고정된 기능을 통해 렌더링 백엔드에 전달됩니다.
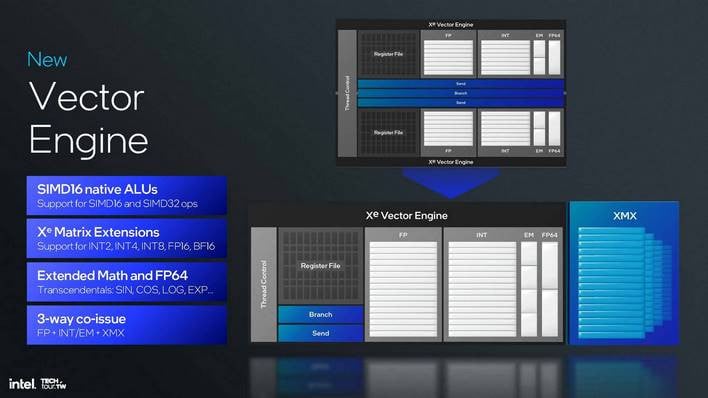
Xe2의 Xe 코어는 기존 Xe 아키텍처의 코어와 매우 다릅니다. 기존 설계가 8폭 SIMD를 사용했다면, Xe2는 16폭 SIMD를 사용하도록 재조정되었습니다. 이는 최신 GPU 아키텍처와 훨씬 더 유사하며, 이러한 변화만으로도 게임 호환성이 크게 개선되어 게임이 제대로 작동하는 데 필요한 드라이버 심이 더 적게 필요합니다.

XVE에 내장된 XMX 유닛은 매우 강력하여 클럭당 2048개의 FP16 연산 또는 INT8 연산에서 4096개의 연산/클럭을 완료할 수 있는 기능을 지원합니다. 이는 당연히 XeSS 업스케일링을 포함한(이에 국한되지 않는) AI 수학을 위한 것입니다. 물론 이 아키텍처가 서버 기반 AI 가속기의 역할에 맞게 조정될 때 Xe2의 성능에도 중요한 역할을 합니다.
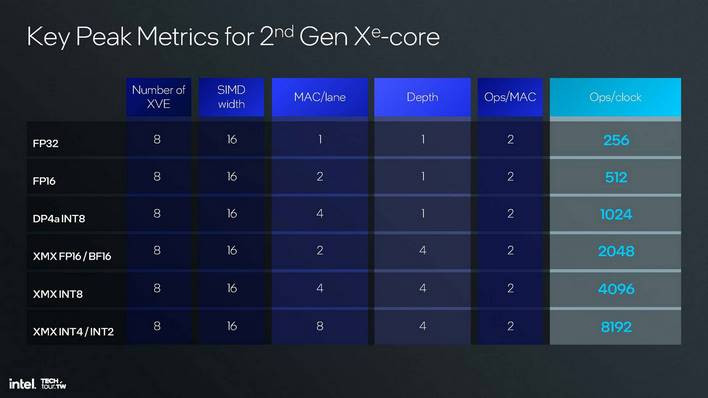
이 차트는 작업 중인 데이터 유형에 따라 매우 크게 달라지기 때문에 모든 사람이 던지는 "TOPS" 숫자를 계산하는 방법을 보여줍니다. 대부분의 사람들은 INT8 TOPS 숫자를 사용하며, 이 값을 찾으려면 관련 코어 수(예: XMX 유닛)에 클럭 속도를 곱한 다음 이 차트에 있는 "Ops/클럭" 숫자를 곱하면 됩니다.
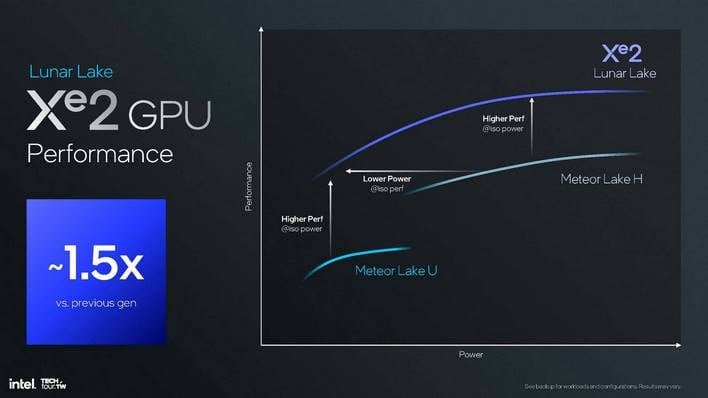
루나 레이크의 Xe2 GPU에 대해 구체적으로 설명하자면, 인텔은 동일한 전력에서 이전 세대 "U" 프로세서보다 약 50% 더 나은 성능을 달성할 수 있으며 이는 경이로운 수치라고 말합니다. 또한 훨씬 더 낮은 전력으로 동일한 성능을 달성할 수 있지만, 더 주목할 만한 점은 더 높은 전력을 사용하는 Meteor Lake H SoC의 Arc GPU를 손쉽게 능가할 수 있다는 점입니다.
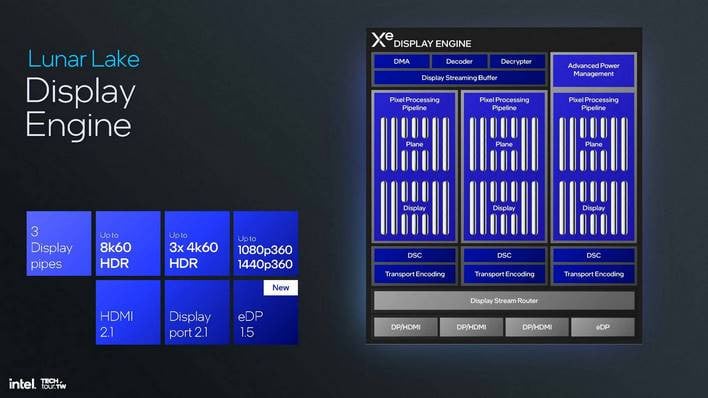
이 슬라이드에서는 인텔이 강조한 루나 레이크의 디스플레이 엔진에 대해 설명하는데, 이는 Xe2가 아닌 루나 레이크에만 해당되는 것입니다. 즉, 이 정보는 배틀메이지와 같은 다른 제품에는 적용되지 않습니다. 특히 루나 레이크는 3개의 디스플레이를 동시에 지원하는데, 디스플레이포트 또는 HDMI 연결 3개 또는 노트북 내부 디스플레이용 eDP 1.5를 통해 2개와 별도의 연결이 가능합니다. 트리플 4K60 모니터 또는 최대 360Hz의 재생률을 지원합니다. 나쁘지 않죠.

eDP 1.5에 대해 말하자면, 이는 상당히 참신한 기능이며 인텔이 최초로 이를 지원합니다. 조기 전송을 통한 선택적 업데이트와 패널 재생을 통한 적응형 동기화 등 몇 가지 멋진 기능이 새롭게 추가되었습니다. 전자의 선택적 업데이트는 디스플레이가 반복되는 프레임의 일부를 가져와서 전송하는 과정을 건너뛰는 것을 말하며, '패널 리플레이'는 새로운 프레임이 준비되지 않은 경우 화면에 동일한 프레임을 다시 표시하는 기능입니다. 이보다 더 좋은 점은 VRR을 사용하여 콘텐츠 재생률을 맞추는 기능도 지원된다는 점입니다.
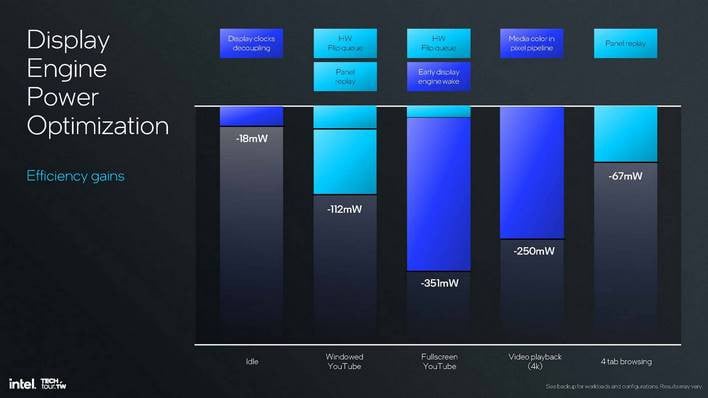
패널 재생, 하드웨어 플립 큐, 디스플레이 엔진 조기 깨우기, 디스플레이 클럭 디커플링 등 인텔이 디스플레이 엔진을 위해 개발한 모든 기술을 결합하면 다양한 일반적인 활동 중에 상당한 전력 절감 효과를 볼 수 있습니다. 가장 큰 이점은 사람들이 몇 시간 동안 계속 시청할 가능성이 높은 YouTube를 전체 화면으로 시청할 때입니다.
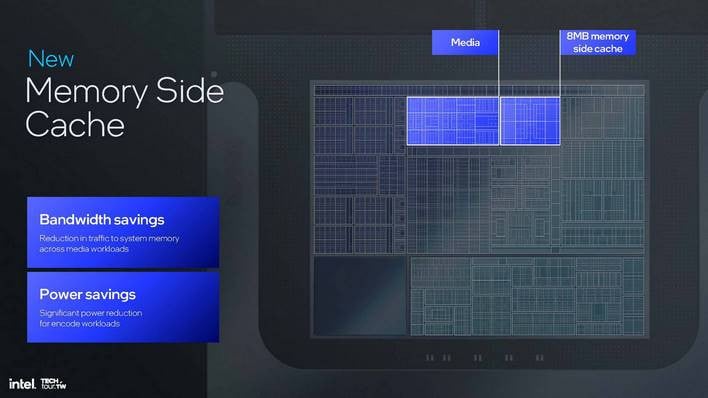
루나 레이크의 미디어 엔진은 메모리 사이드 캐시 추가 등 주요 변경 사항도 있습니다. 이는 시스템 수준의 캐시 역할을 하지만 미디어 디코딩 및 인코딩 작업에서 전력을 크게 절약할 수 있기 때문에 여기서 언급하는 것입니다. 8MB 캐시는 기본적으로 RAM에서 나오는 모든 데이터를 캐시하여 상대적으로 전력이 많이 소모되는 메인 메모리로 이동하지 않아도 됩니다.
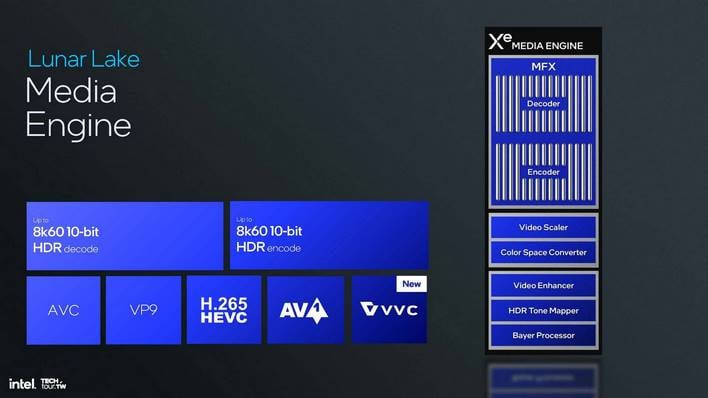
미디어 엔진 자체는 기능 면에서 상당히 뛰어나지만, Lunar Lake에는 단일 MFX만 있기 때문에 단일 동시 비디오 스트림만 지원한다는 점에 유의해야 합니다. 하지만 인코딩이든 디코딩이든 스트림은 최대 8K60까지 가능하며 채널당 10비트 HDR이 완벽하게 지원됩니다. 또한 개정된 미디어 블록은 현재 디코딩만 지원하지만 새로운 H.266 다목적 비디오 코딩 표준에 대한 지원도 추가했습니다.

물론 드라이버는 그래픽 성능의 중요한 부분이며, 인텔은 그래픽 드라이버를 개선하기 위해 노력해 왔습니다. 2년 전 완전히 다른 패러다임에 기반한 DirectX 9 드라이버가 출시되었고, Xe 아키텍처 출시 이후 27개월 동안 전반적으로 성능이 꾸준히 향상되었습니다. 인텔은 출시 당시 Xe2의 드라이버 상황은 알케미스트용 그래픽 소프트웨어의 불안정한 상태와는 완전히 다를 것이라고 확신하고 있으며, 저희도 그렇게 믿고 있습니다.
인텔 루나 레이크 심층 분석: NPU4, 스레드 디렉터, 그리고 초기 결론

루나 레이크 프로세서 아키텍처에 대한 논의에서 AI 성능과 NPU에 대한 이야기를 빼놓을 수 없습니다. 위 슬라이드는 루나 레이크가 AI 처리를 위해 최대 120 TOPS를 제공할 수 있다고 자랑스럽게 소개합니다. 이 성능의 대부분은 Xe2 GPU와 64개의 XMX 유닛에서 나오는 반면, AMX가 없는 CPU는 5개의 TOPS만 제공합니다. 나머지는 통합 NPU에서 제공됩니다.
Lunar Lake Quadrules, Meteor Lake에 대한 NPU 성능
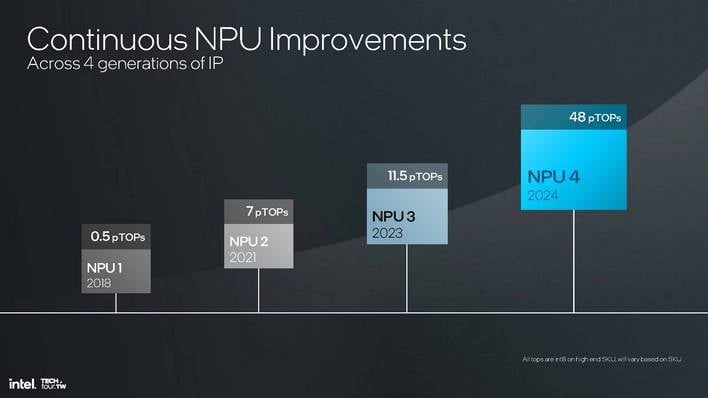
인텔은 루나 레이크 NPU의 아키텍처를 "NPU 4"라고 설명하는데, 이는 4세대 NPU라는 의미입니다. 인텔은 2018년의 Movidius Myriad X를 기반으로 한 오리지널 애드온 NPU 실리콘에서 이를 계산하고 있습니다. "킹 베이" AI 프로세서는 차세대 프로세서였고, Meteor Lake의 통합 NPU는 3세대 AI 프로세서였습니다. 이제 루나레이크는 최대 48개의 TOPS를 제공하는 4세대 제품입니다.

NPU4는 구조적으로 NPU3보다 확실히 개선되었으며, 이에 대해서는 간략히 살펴보겠지만, Meteor Lake NPU와 Lunar Lake NPU의 가장 큰 차이점은 단순히 규모의 문제입니다. 신경 프로세서 내부의 기능 유닛 수와 클럭 속도가 모두 증가하여 백그라운드 AI 처리 능력이 4배 이상 향상되었습니다.

루나 레이크 NPU가 말 그대로 메테오 레이크의 3배 크기라는 점을 고려하면 이해가 됩니다. 신경 연산 엔진의 수도 세 배로 늘어났으며, 마찬가지로 MAC(곱하기 및 누적) 유닛의 수도 세 배로 늘어났습니다.

다이 축소 덕분에 클럭 속도가 불특정(아마도 약 33%)으로 증가하면서 인텔은 NPU4가 NPU3에 비해 동일한 전력으로 두 배의 성능을 낼 수 있으며, 앞서 언급한 것처럼 최고 성능은 약 4배 빠르다고 말합니다. 이는 퀄컴의 스냅드래곤 X 엘리트 및 AMD의 라이젠 AI 300 프로세서와 같은 범위에 속하며, 마이크로소프트가 코파일럿+ PC의 최소 요구 사항으로 40 TOPS를 의무화했기 때문에 우연이 아닙니다.

NPU4에서 가장 큰 변화는 벡터 레지스터의 크기를 4배로 늘리고 DSP 안팎의 대역폭을 4배로 늘린 SHAVE DSP에 적용된 것으로 보입니다. 이러한 DSP는 AI 처리를 위한 중요한 벡터 연산을 수행하므로 이러한 변화는 NPU의 기능을 근본적으로 개선한 것입니다.
댓글 (5)
-
 블
블블링블링종현

24.06.05 · 14.♡.205.140
설명은 늘 역대급이었던 인텔.....과연 이번에는 다를지..... - 다
다시머리에꽃을
24.06.05 · 124.♡.159.183
지난 메테오레이크에서 입털었던거 생각하면... 실제 제품이 나와봐야 합니다 -
 칼
칼칼쓰뎅
24.06.05 · 119.♡.210.192
오잉... DRAM 붙여버린건가요 ㄷㄷㄷ -
 물
물물갈낭구
24.06.06 · 180.♡.27.218
메테오레이크 때의 자료와 비교해서 보면 더 재미있습니다.
https://coolenjoy.net/bbs/38/4837234 -
 돔
돔돔황챠
24.06.10 · 210.♡.11.78
{emo:damoang-emo-025.gif:50}{emo:onion-035.gif:50}
댓글을 작성하려면 이 필요합니다.